转载 | SSTable and Log Structured Storage: LevelDB
如果说Protocol Buffers 是谷歌(Google)中个人数据记录的通用语言(lingua franca),那么排序字符串表(Sorted String Table,简称 SSTable)就是用于存储、处理和交换数据集的最受欢迎的输出格式之一。正如其名称所暗示的,SSTable 是一种简单的抽象,用于高效地存储大量键值对,同时优化高吞吐量的顺序读/写工作负载。
不幸的是,SSTable 这个名称本身也被业界过度使用,用来指代远远超出排序表本身的服务,这只会增加对本质上非常简单且有用的数据结构的混淆。接下来让我们仔细看看 SSTable 的内部结构,以及 LevelDB 如何利用它。
SSTable: Sorted String Table
想象一下,我们需要处理一个输入数据量达到数千兆字节(Gigabytes)或数万亿字节(Terabytes)的大型工作负载。此外,我们还需要对其执行多个步骤,每个步骤必须由不同的二进制程序完成——换句话说,想象我们正在运行一系列 Map-Reduce 任务!由于输入数据量庞大,数据的读写操作可能会成为运行时间的瓶颈。因此,随机读写不是一个可行的选项,我们更希望以流式方式读取数据,处理完成后再以流式操作将数据刷新回磁盘。通过这种方式,我们可以摊销磁盘 I/O 成本。没有什么革命性的,只是在顺利推进而已。

“排序字符串表”(Sorted String Table)顾名思义,就是一个文件,里面包含一组任意的、已排序的键值对。允许存在重复的键,不需要对键或值进行“填充”,键和值都是任意的数据块。顺序读取整个文件,就相当于拥有了一个排序索引。可选地,如果文件非常大,我们还可以在前面添加或创建一个独立的 key:offset 索引,以实现快速访问。SSTable 就是这样一个东西:非常简单,但也是一种非常有用的方式,用于交换大型排序好的数据片段。
SSTable and BigTable: Fast random access?
一旦 SSTable 存储到磁盘上,它实际上是不可变的,因为插入或删除操作将需要对整个文件进行大量的 I/O 重写。不过,对于静态索引来说,这是一种很好的解决方案:读取索引,你总是只需进行一次磁盘查找,或者简单地将整个文件映射到内存中(mmap)。随机读取操作既快速又简单。
而随机写入则要困难且昂贵得多,除非整个表都存放在内存中,这时我们就可以回到简单的指针操作。事实证明,这正是 Google 的 BigTable 试图解决的问题:如何针对规模达到 PB 级的数据集实现快速的读写访问,并且底层依靠的是 SSTable。他们是怎么做到的呢?
SSTables and Log Structured Merge Trees
我们希望保留 SSTable 带来的快速读取访问,同时也希望支持快速的随机写入。事实证明,我们已经具备了所有必要的条件:当 SSTable 在内存中时(我们称之为 MemTable),随机写入是快速的;如果表是不可变的,那么存储在磁盘上的 SSTable 也同样可以快速读取。现在,让我们介绍以下约定:
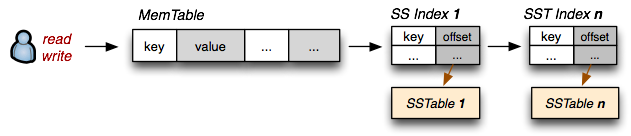
- 磁盘上的 SSTable 索引总是被加载到内存中
- 所有写入操作直接写入 MemTable 索引
- 读取操作先检查 MemTable,然后再检查 SSTable 索引
- 定期将 MemTable 刷写到磁盘,形成 SSTable
- 定期将磁盘上的多个 SSTable 进行“合并”
我们这里做了什么?写入操作总是在内存中进行,因此速度总是很快。一旦 MemTable 达到一定大小,就会被刷新到磁盘,形成一个不可变的 SSTable。然而,我们会将所有 SSTable 索引都保存在内存中,这意味着每次读取时,我们可以先检查 MemTable,然后依次查找 SSTable 索引序列来定位数据。事实证明,我们刚刚重新发明了由 Patrick O'Neil 描述的“日志结构合并树”(The Log-Structured Merge-Tree,LSM Tree),这也是 Google “BigTable Tablets” 背后的核心机制。
LSM & SSTables: Updates, Deletes and Maintenance
这种“LSM”架构带来了许多有趣的特性:写入操作始终快速(只追加写入),而随机读取要么直接从内存中提供,要么只需一次快速的磁盘查找。那么,更新和删除操作该怎么办呢?
一旦 SSTable 存储到磁盘上,它就是不可变的,因此更新和删除操作无法直接修改数据。相反,最近的值会存储在 MemTable 中以便更新,而删除操作则会追加一个“墓碑”(tombstone)记录。由于我们按顺序检查索引,后续的读取会找到更新后的数据或墓碑记录,而不会访问旧的数据。最后,磁盘上存在数百个 SSTable 也不是一个好主意,因此我们会定期运行一个合并过程,将磁盘上的 SSTable 合并,在这个过程中,更新和删除的记录会覆盖并移除旧的数据。
SSTables and LevelDB
取一个 SSTable,加入一个 MemTable,并应用一套处理约定,你就得到了一个适合某些特定工作负载的优秀数据库引擎。实际上,Google 的 BigTable、Hadoop 的 HBase 和 Cassandra 等系统,都是使用这种架构的变体或直接拷贝。
表面上看很简单,但实现细节非常重要。幸运的是,Jeff Dean 和 Sanjay Ghemawat,这两位 Google SSTable 和 BigTable 基础设施的主要贡献者,于去年早些时候发布了 LevelDB,这基本上是上述架构的一个精确复制版本,具有以下特点:
- 底层使用 SSTable,写操作通过 MemTable 完成
- 键和值都是任意的字节数组
- 支持 Put、Get、Delete 操作
- 支持数据的前向和反向迭代
- 内置 Snappy 压缩
LevelDB 被设计为 WebKit 中 IndexDB 的引擎(即嵌入在你的浏览器中),具有易于嵌入、速度快的特点,最重要的是,它自动处理所有 SSTable 和 MemTable 的刷新、合并及其他复杂细节。
Working with LevelDB: Ruby
LevelDB 是一个库,而不是独立的服务器或服务——虽然你完全可以在它之上轻松实现一个。要开始使用,可以获取你喜欢的语言绑定(ruby),接下来让我们看看能做些什么:
# gem install leveldb-ruby
db = LevelDB::DB.new
db.put ,
db.put ,
db.put ,
puts db.get # => foo
db.each do
p [k,v] # => ["a", "foo"], ["b", "bar"], ["c", "baz"]
end
db.to_a # => [["a", "foo"], ["b", "bar"], ["c", "baz"]]
我们可以用几行代码来存储键、检索键以及执行范围扫描。MemTable 的维护、SSTable 的合并等其他工作都由 LevelDB 负责处理——既简洁又方便。
LevelDB in WebKit and Beyond
SSTable 是一种非常简单且实用的数据结构,是一种优秀的大批量输入/输出格式。然而,使 SSTable 快速(有序且不可变)的特性也暴露出它的一些局限性。为了解决这些问题,我们引入了 MemTable 的概念,以及一套用于管理众多 SSTable 的“日志结构”处理约定。
这些都是简单的规则,但如往常一样,实现细节非常重要,这也是为什么 LevelDB 能成为开源数据库引擎栈中的一个优秀补充。很可能,你很快就在浏览器、手机以及许多其他地方发现 LevelDB 的身影。你可以查看 LevelDB 的源码,浏览文档,并亲自试用一下。