转载 | 如何应对突发流量激增或“惊群效应”?
What is the Thundering Herd Problem?
想象这样一种场景:某个事件导致你的一项或多项服务流量骤增,超出了它们的处理能力。这可能会导致一个或多个依赖服务(比如数据库)过载并变得无响应,最终引发服务故障(级联故障)。此类事件可能包括多个服务实例失败,所有流量被重定向到单个实例;一张病毒式传播的图片或视频获得大量观看;或者节日期间的线上促销活动导致数据库超载。这种由级联故障引起的服务不可用,因突发流量激增而发生的情况,称为“惊群效应”(Thundering Herd Problem)。
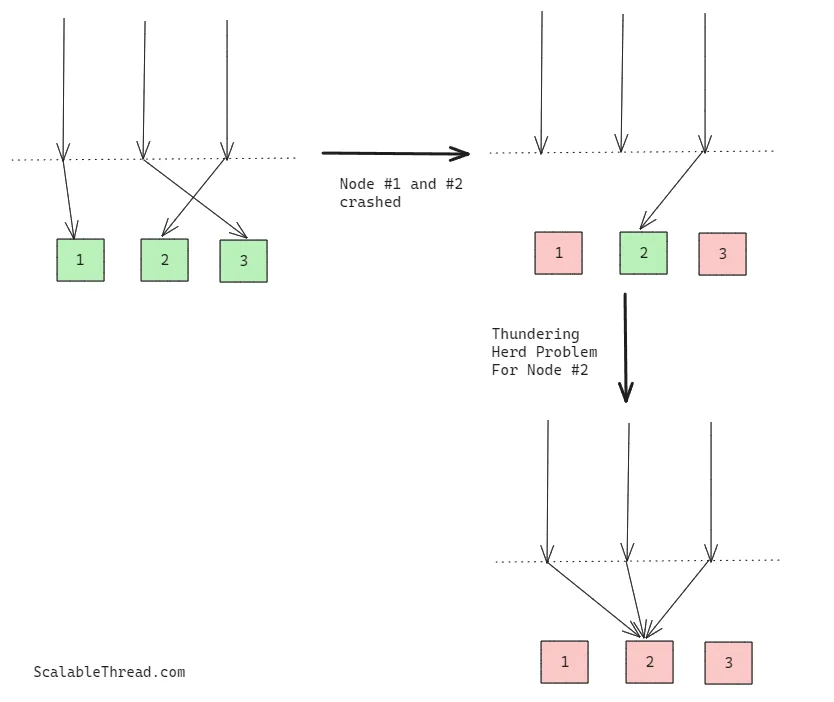
How to Handle the Situation?
Exponential Jitter and Retry(指数抖动与重试)
当某个服务未能响应时,直觉上的解决方案是重试请求,假设这是一次短暂的故障。然而,这种方法可能导致惊群效应,或者加剧已有的惊群效应,因为所有客户端会同时重试,导致系统资源被压垮。相反,如果客户端在随机间隔时间内重试,过载的资源就有时间恢复并响应。这种重试时间的随机性称为“抖动”(Jitter),有助于更均匀地分配负载,防止系统遭受进一步的压力。
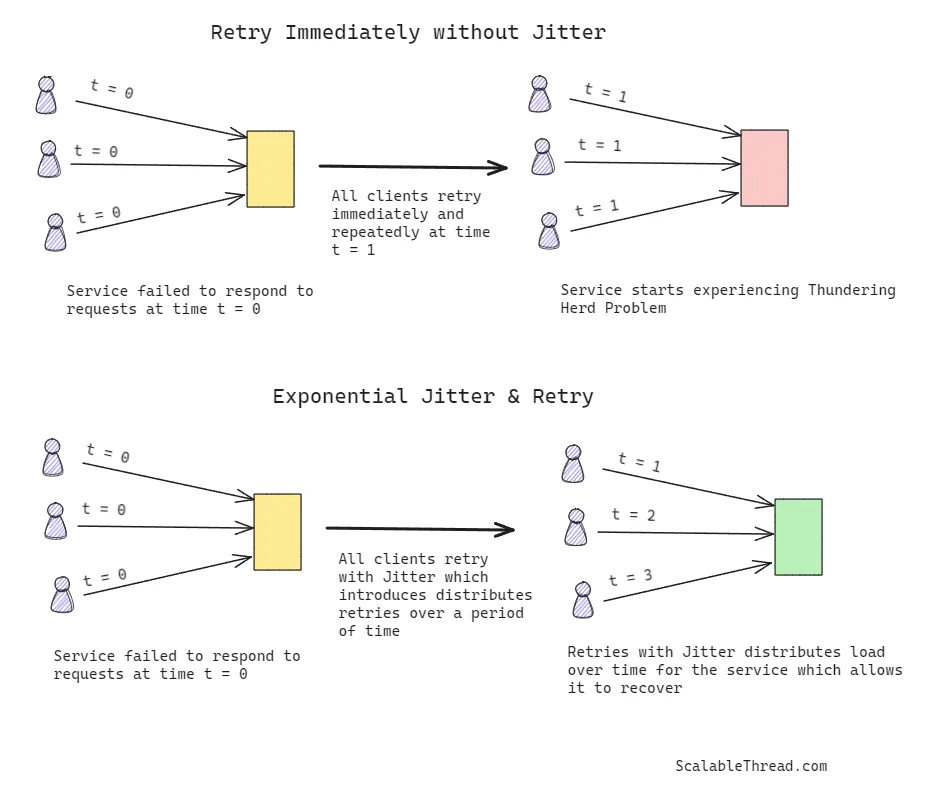
“抖动”(Jitter)指的是在固定等待时间的基础上,随机加上或减去一段时间,使得每次重试的间隔时间不完全相同。
抖动(Jitter)本身并不能解决服务响应失败的根本原因,比如服务器过载、网络故障或者代码错误。不过,抖动的作用在于减轻由于大量客户端同步重试引起的额外压力,防止“惊群效应”恶化问题。
- 当服务暂时过载时,如果所有客户端都在固定的时间点(比如3秒)同时重试,瞬间会产生大量请求涌入,导致服务压力骤增,更可能让服务继续失败。
- 通过抖动,让客户端的重试时间分散开来,服务得以“喘息”恢复部分处理能力,而不是被一波又一波同步请求压垮。
- 这样,虽然服务仍可能因负载大而失败,但它的恢复速度会更快,整体系统的稳定性和可用性更好。
简单比喻就是: 如果一扇门很窄,很多人同时撞击会更容易把门撞坏;如果大家错开时间进门,门可以更平稳地应付人流,减少损坏。
所以,抖动是配合其他手段(如限流、降级、扩容等)来提升系统健壮性的一个重要策略,能有效避免雪上加霜。
Queueing Requests(排队请求)
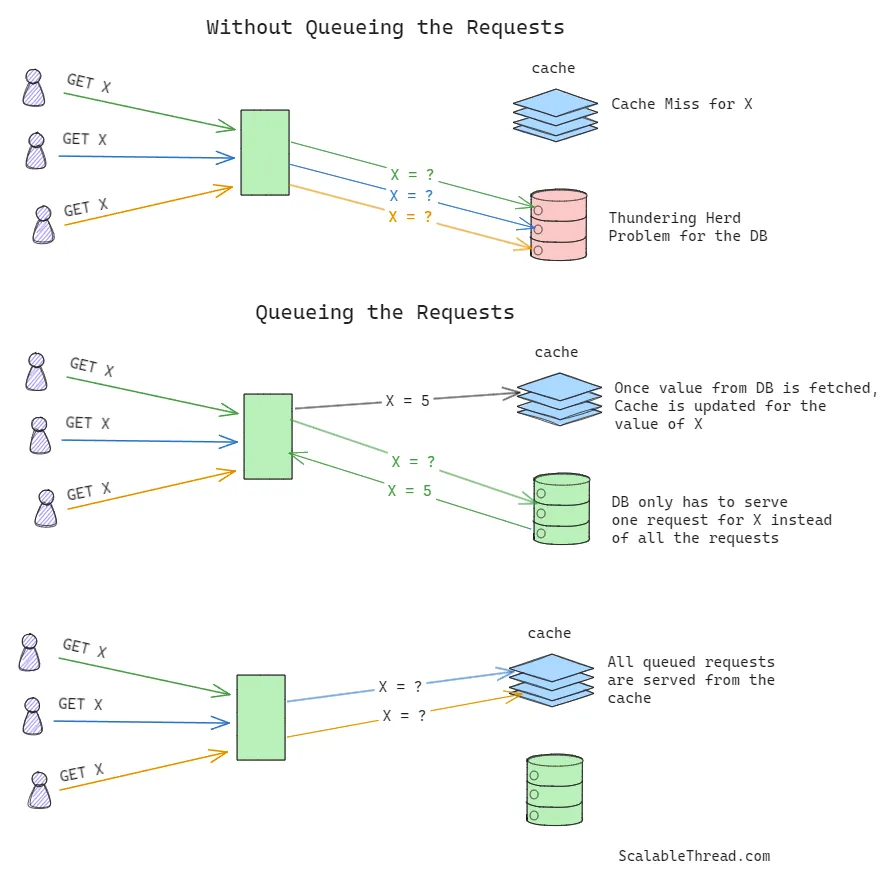
考虑这样一种情景:请求从缓存中获取某张图片时发生缓存未命中,导致请求被转发到源数据存储进行处理。如果大量同时请求都发生缓存未命中,并被转发到数据存储,就可能引发惊群效应。由于所有请求都是针对同一张图片,只有一个请求应该被转发到数据存储来完成处理。其他请求可以排队等待,并在初始请求从数据存储返回后,缓存被更新后,再从缓存中进行响应。
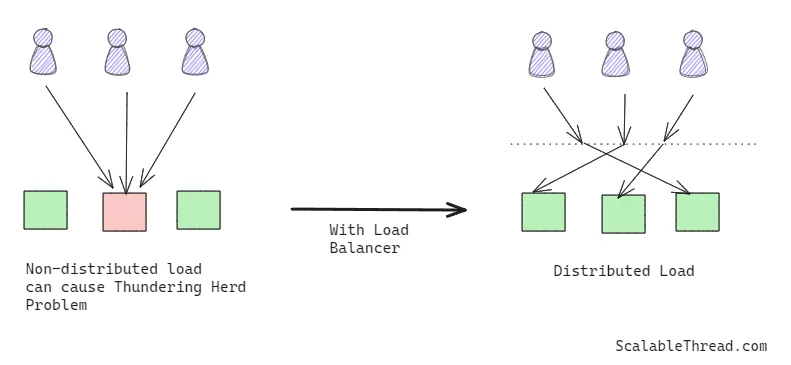
Load Balancing(负载均衡)
每个大规模应用在某个阶段都需要在后端进行服务复制来应对不断增加的流量。然而,如果流量没有均匀分布到所有服务副本上,可能会导致某些实例负载过重。使用负载均衡器将负载均匀分配,有助于防止惊群效应的发生。
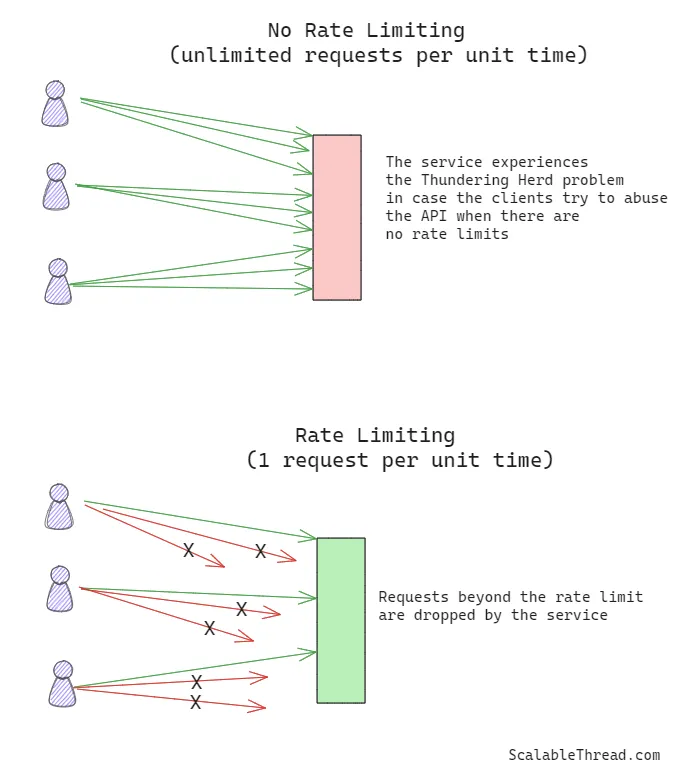
Rate Limiting(速率限制)
如果一个服务开放了API,给客户端提供无限制的访问权限,当一个或多个客户端滥用时,可能会造成灾难性后果。像DDOS攻击或定时批处理作业这类场景都可能引发惊群效应。通过实现速率限制来控制客户端调用API的频率,可以帮助管理高吞吐量的客户端,防止此类问题的发生。
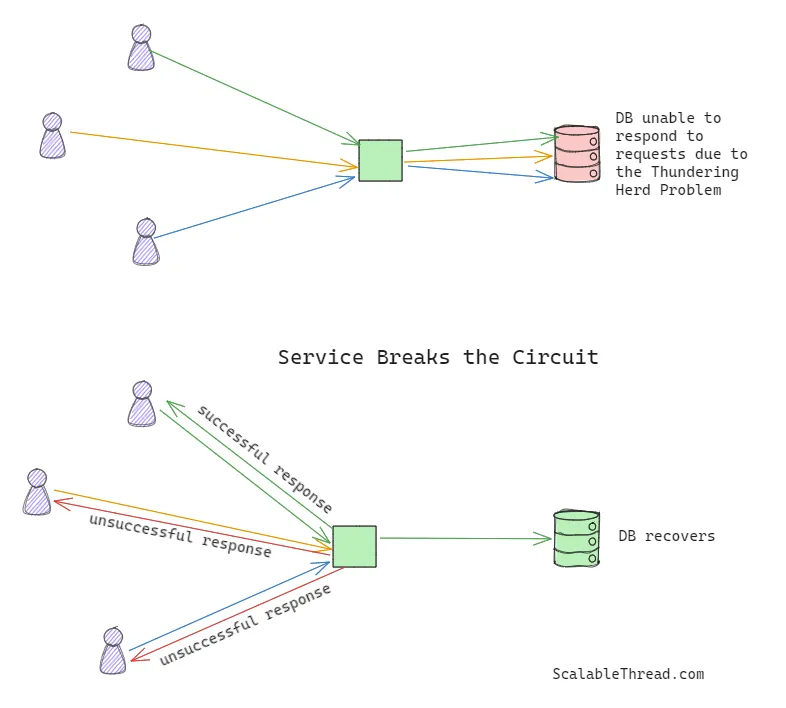
Circuit Breaker(断路器)
服务依赖项(例如数据库)可能会因惊群效应而失败。类似于微型断路器(MCB)通过在电压突然升高时断开电路来保护电路,服务也可以实现断路器机制。这种方式会暂停向依赖项发送更多的请求,直到依赖恢复并准备好再次处理流量为止。
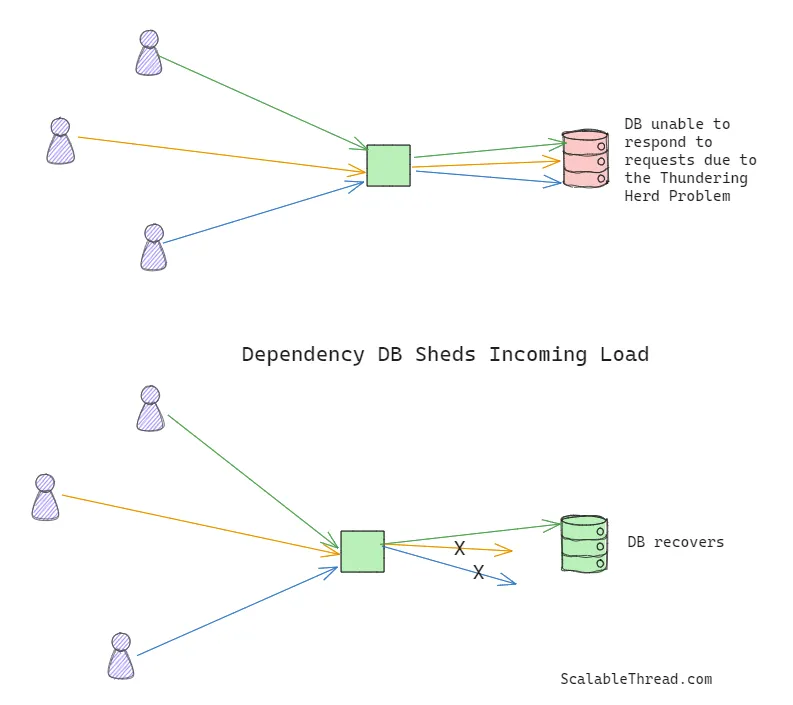
Load Shedding(负载卸载)
虽然断路器允许服务停止向依赖项发送请求,但依赖项自身仍可以丢弃进入的请求,这种技术称为负载卸载,用以防止惊群效应。这类似于电力系统中的轮流停电,电力供应商通过降低负载来防止当需求超过容量时导致整个系统崩溃。
Circuit Breaker和Load Shedding的区别
- Circuit Breaker(断路器):当检测到依赖服务不可用或负载过高时,断路器会“断开”请求通路,阻止服务继续向该依赖发送请求,但通常会快速返回一个失败响应,告知调用方请求未被处理。
- Load Shedding(负载卸载):依赖服务本身主动丢弃一部分请求,不予处理,不返回具体错误响应,目的是减轻自身压力,防止系统整体崩溃。
简而言之,断路器是请求端主动停止发送请求,而负载卸载是依赖端主动丢弃请求。两者都是为防止系统过载,缓解“惊群效应”的重要手段,但侧重点和实现位置不同。