转载 | NoSQL数据库如何加速写密集型工作负载?
Understanding the Problem
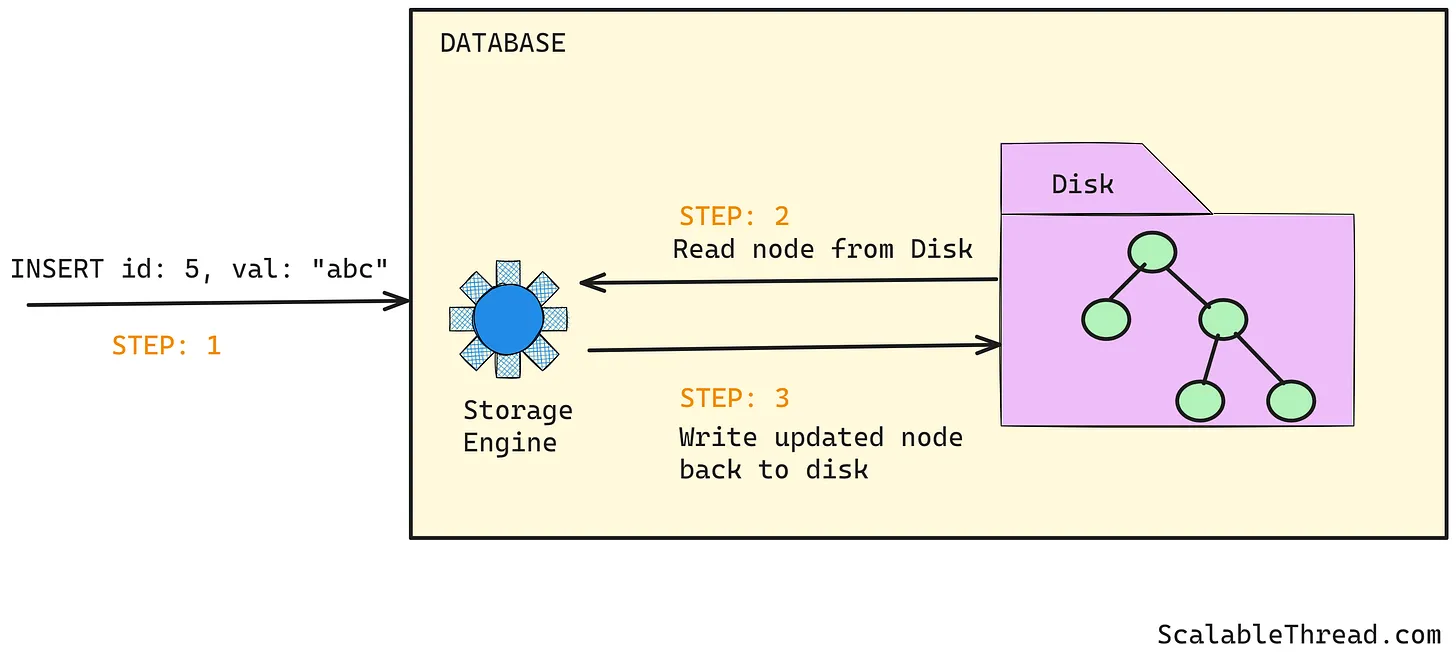
在依赖B树的数据库(例如MySQL、PostgreSQL等)中,写入数据需要找到适当的树节点(或多个节点)来添加新数据,先从磁盘中读取该节点,进行更新操作,然后再将节点写回磁盘。在某些情况下,树结构可能还需要重新平衡(比如新节点被创建时)。换句话说,为了写入几字节的数据,需要从磁盘上随机位置读取一个或多个几个千字节大小的树节点,更新它们,再写回磁盘。这样的随机磁盘I/O(这会增加延迟)以及高读写比例(读取数据大小与写入新数据大小之比)都会影响整体的写入性能。
What is a Log Structured Merge (LSM) Tree?
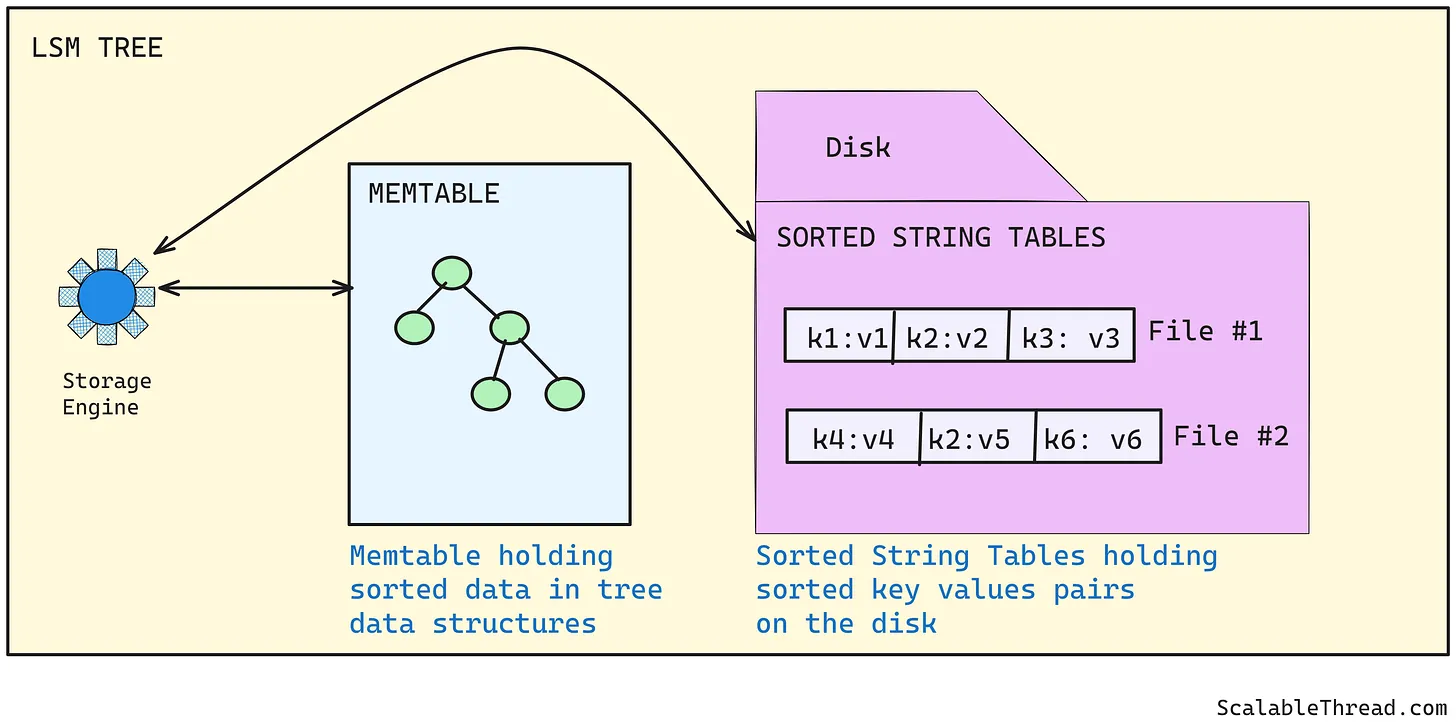
LSM树是一种优化数据库(如Cassandra、YugabyteDB等)写入性能的数据结构,通过在内存中缓冲写入操作,并定期将这些写入批量刷新到磁盘。由于这些写入是顺序地刷新到磁盘的(顺序磁盘I/O的延迟低于随机磁盘I/O),因此提升了写入效率。LSM树通过两个主要组件来实现这一点:
1) Memtable
Memtable是一种内存中的数据结构(类似AVL树),用于按键排序保存键值对数据。相比B树将数据保存在磁盘上(随机磁盘I/O)并保持排序,内存中的memtable数据保持排序更快。这使得对有序memtable的读写操作速度更快。所有写入操作先写入内存中有序的memtable,当memtable满了之后,才将其刷新到磁盘。
2) Sorted String Tables (SSTables)
一旦memtable满了,它会被刷新到磁盘上以追加方式存储的有序字符串表(SSTables)文件中(不允许更新)。SSTables中的数据是按键排序的,对于同一个键,文件中后出现的值比前面出现的值更新。
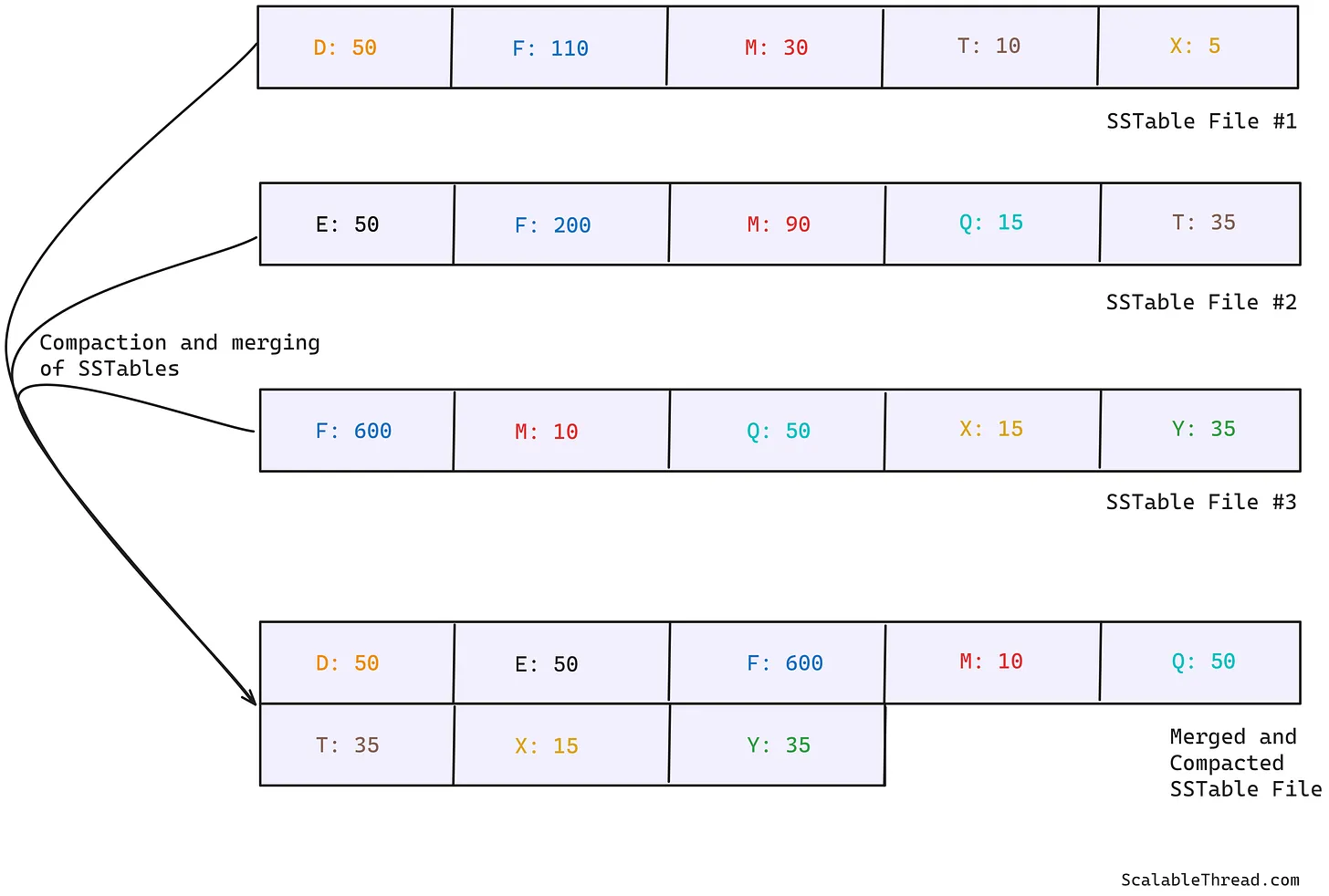
Understanding Compaction in SSTables
当memtable满了之后,它会被写入磁盘,作为按键排序的SSTable文件。多次memtable刷新会产生多个SSTable文件。随着时间推移,同一个键可能会出现在不同的SSTable文件中,因为数据库中的键可以在不同时间被更新为不同的值,而SSTables是追加写入的。这意味着相比之前的memtable刷新,最近一次的memtable刷新会包含给定键的当前值。
为了保持数据为最新的值,SSTables会不定期地运行合并与压缩(merge and compaction)过程,将多个SSTable文件合并成一个。该过程如下进行:
- 从每个SSTable文件的顶部读取第一个条目,比较它们的键;
- 将键值对中键最小的那一对添加到新的SSTable文件中。如果所有文件中包含相同键但对应不同的值,则视为最近更新的文件中的键值对(因为它包含最新更新),其他的都被丢弃;
- 该过程重复进行,直到所有文件中的键值对都被移动到新的合并压缩后的文件中。
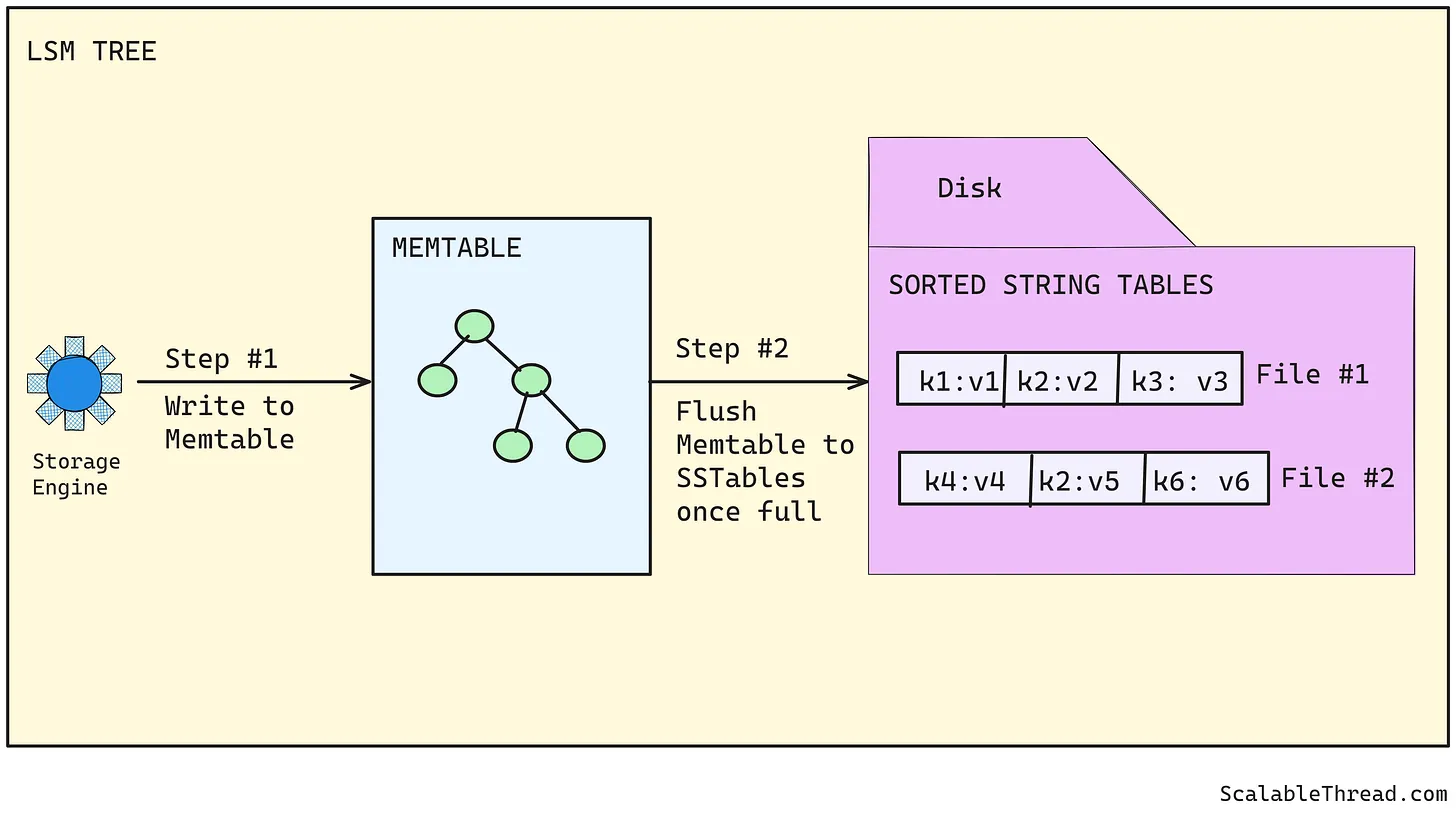
Writes in LSM Trees
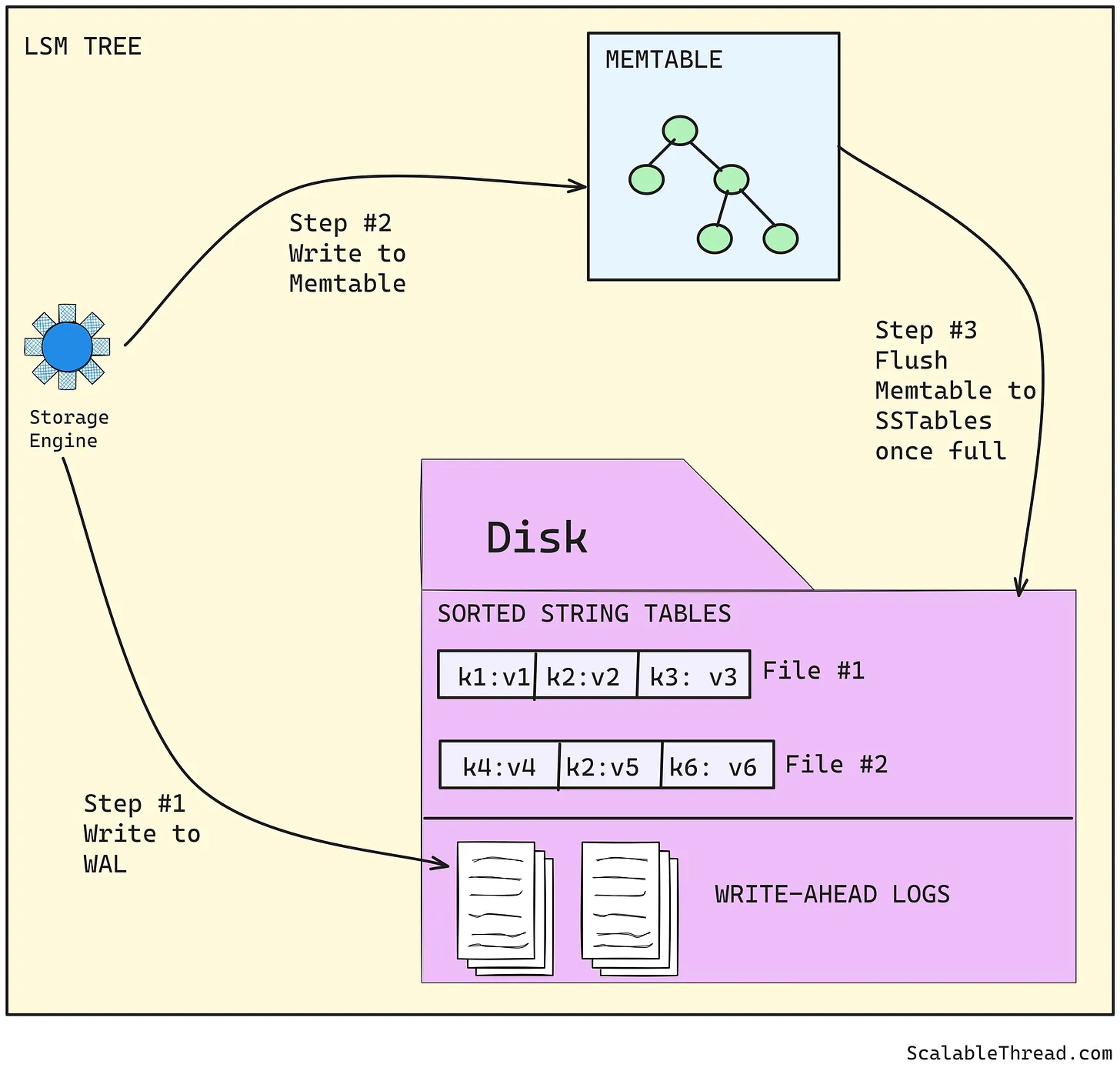
- 写入操作首先写入memtable(保持数据按键排序);
- 一旦memtable满了,它被顺序地以有序且追加写入(sequentially)的方式写入磁盘,形成一个SSTable文件。由于memtable已经保持数据的排序,这不会影响性能。这使得LSM树能够支持高写入吞吐量;
- 在一定时间间隔内,不同的SSTable文件会被合并和压缩。
What Happens to Memtable Data in Case of a Crash?
由于memtable是保存在内存中的,数据库崩溃可能导致这些数据丢失。为了解决这个问题,memtable中的数据也会写入预写日志(Write-Ahead Logs,WAL Logs)。如果发生崩溃,memtable可以通过WAL日志重建,一旦memtable被刷新到磁盘,其对应的WAL日志就会被丢弃。
Reads in LSM Trees
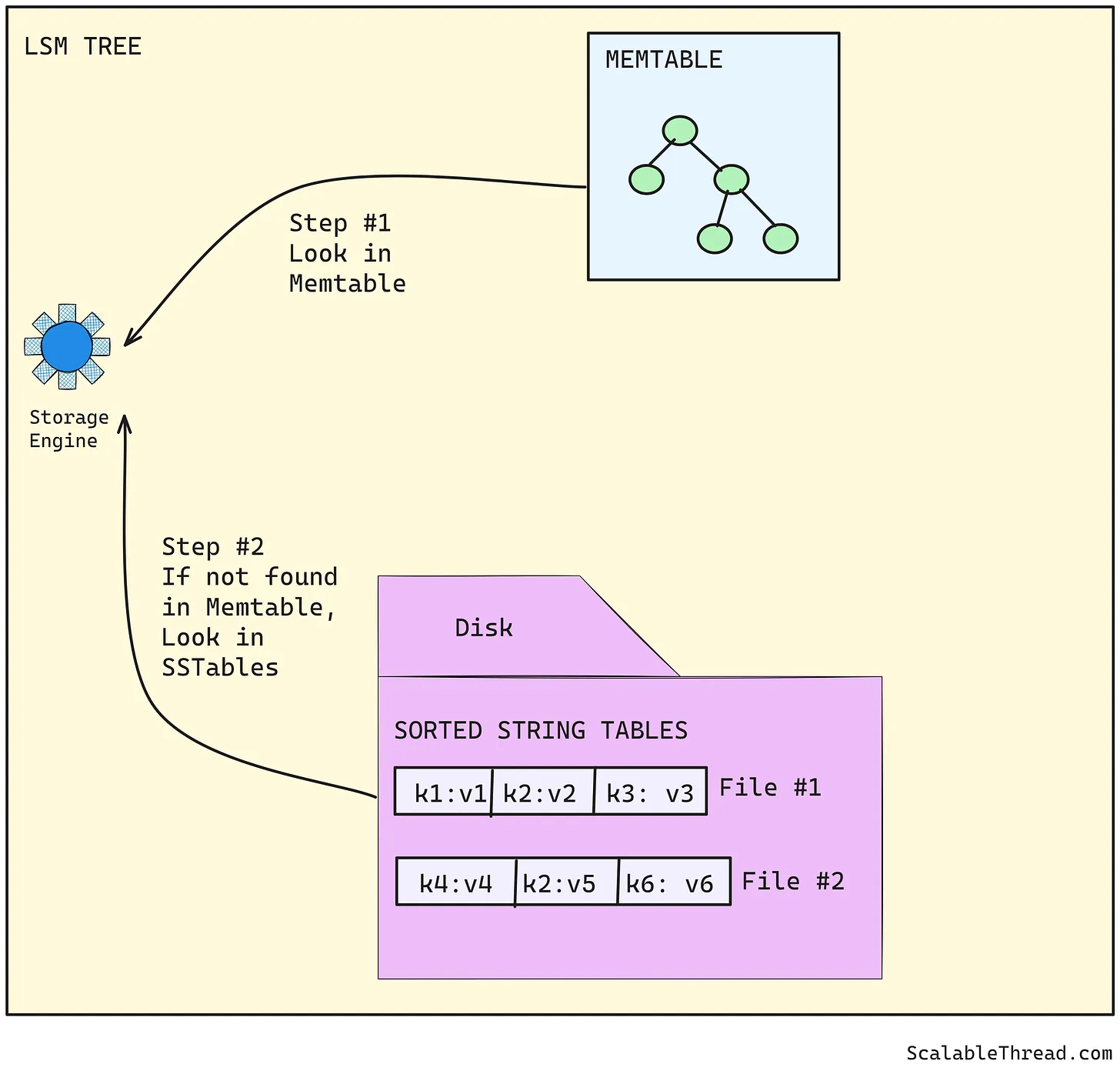
- 要读取的键首先会在memtable中搜索。由于memtable在内存中,查找速度很快。
- 如果在memtable中找不到该键,则会在最近刷新到磁盘的SSTable文件中查找。如果仍然找不到,再到更老的SSTable文件中查找,依此类推。这是因为读取操作可能会在所有SSTable文件合并压缩为一个文件之前发生。
How are Reads Optimized?
扫描SSTable文件会影响读取性能。为了优化读取:
- 常用布隆过滤器(Bloom Filters)来判断一个键是否存在于SSTable中;
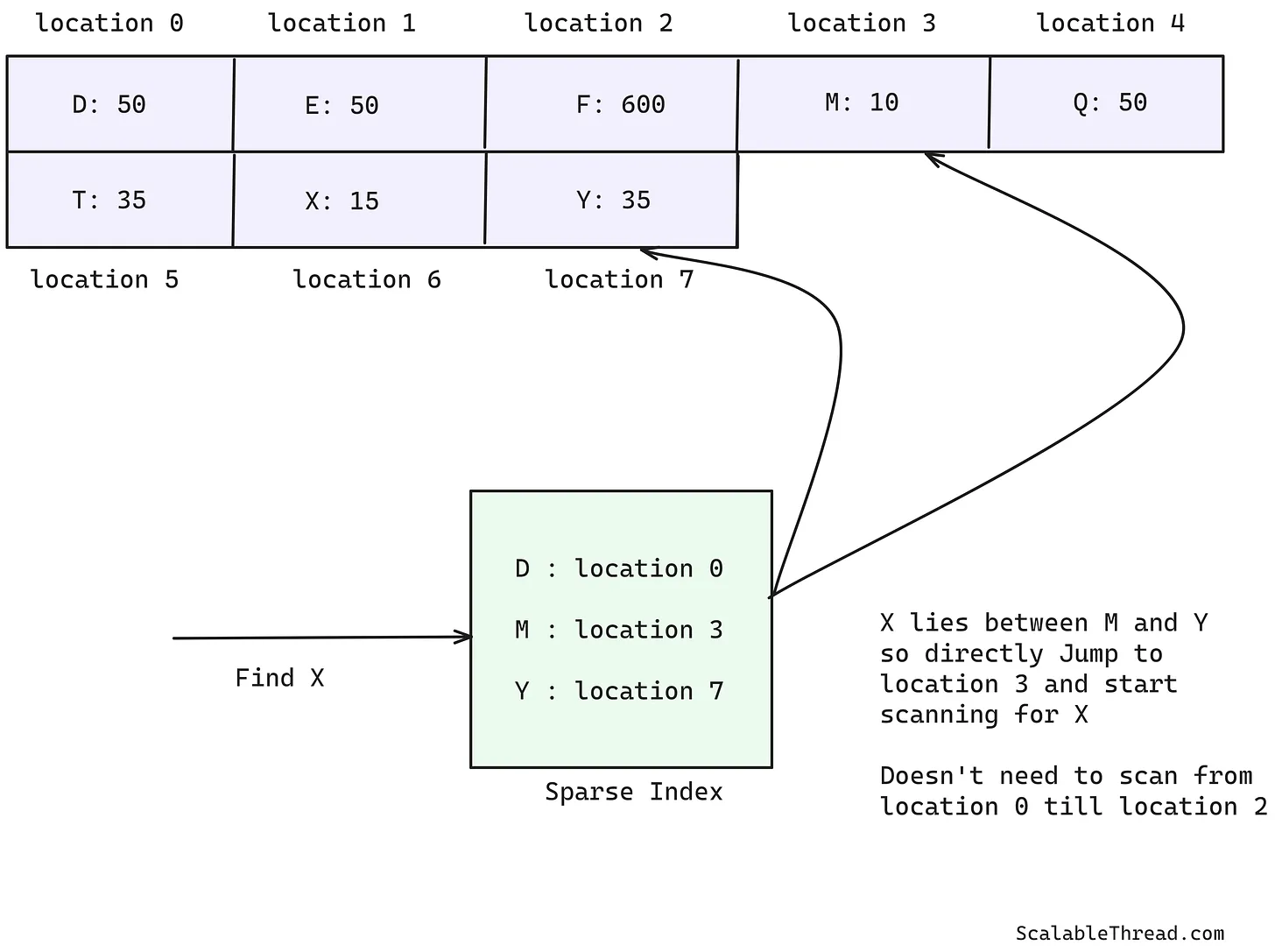
- 在内存中为部分键创建了一个稀疏索引(sparse index)用于SSTable。该索引包含少量键及其在SSTable文件中的位置。任何键的读取首先会在该稀疏索引中查找,找到目标键之前和之后的键对应的位置。由于SSTable中的数据是有序的,目标键必定位于这两个位置之间。这样就加快了读取速度,因为只需扫描这两个位置之间的键即可找到目标键。这类似于在字典中查找一个单词,我们不需要逐字扫描整个字典,而是查找位于目标单词之前和之后的两个单词之间的列表。
- https://newsletter.scalablethread.com/p/how-lsm-trees-optimize-write-heavy
- Wikipedia contributors. (2024b, September 13). B-Tree. Wikipedia.
- Kleppmann, M. (2017, Chapter 3). Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. “O’Reilly Media, Inc.”
- Sadeghi, Y. (2024, February 7). What is a Log Structured Merge Tree? Definition & FAQs | ScyllaDB. ScyllaDB.
- Log structured merge(LSM) tree and Sorted string table (SST). (2024, April 22). YugabyteDB Docs.