转载 | 数据库如何通过预写日志(Write-Ahead Logs)避免数据丢失?
故障是系统设计无论多么完善都必然会发生的一个属性,数据库也不例外!数据库在崩溃或故障后重启时,应该能够恢复到崩溃前的状态。除了故障处理之外,拥有多个副本的分布式数据库必须保持高性能和低延迟。这通过一种称为预写日志(Write-Ahead Logs,简称 WAL)的技术来实现。
What are Write-Ahead Logs?
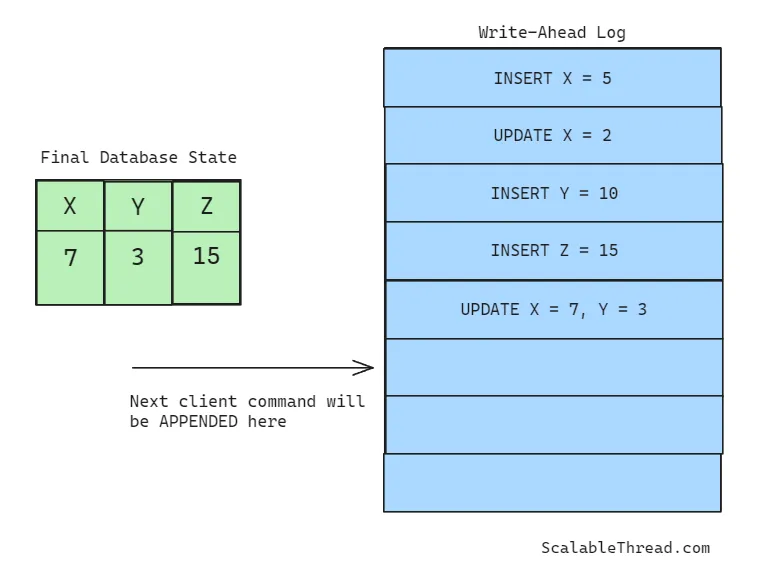
数据库系统中的每个节点都会在持久存储中维护一个只追加的日志文件,客户端发送到该节点的每个更新操作首先被追加(写前日志)到该文件中,随后再应用到数据库中的数据。这种日志技术被称为写前日志(Write-Ahead Logging),因为更新命令是在对数据实际进行更新之前先写入日志的。
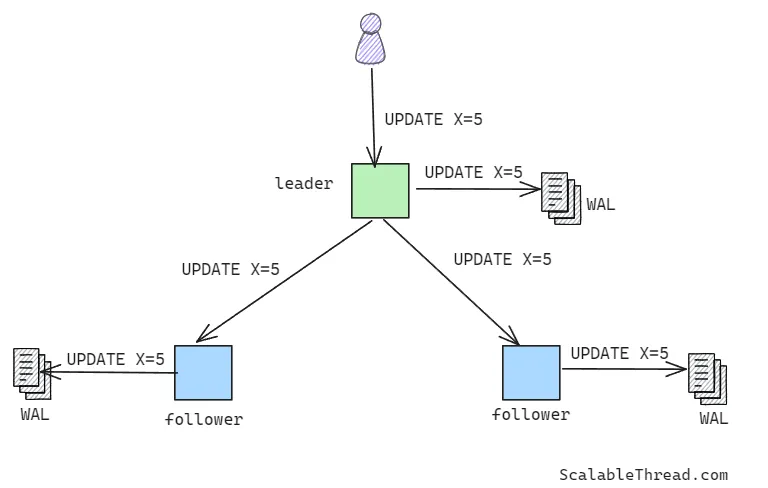
预写日志(WAL)并不保存数据库中实际的数据状态,而是将每条日志记录作为客户端发送给数据库的查询或命令的副本。一旦查询被写入日志文件,就会在数据库中存储的数据上执行该查询。
How does WAL Help Prevent Data Loss?
预写日志被写入持久存储(如磁盘),使其能够在节点故障后仍然存活。在分布式数据库中,一旦跟随节点在故障后重启,它会从头开始读取其预写日志文件,并依次执行日志文件中的更新操作。这样该节点就能恢复到故障发生前的状态。可以把它想象成银行对账单列出了所有的借记和贷记交易,如果这些交易逐一作用于初始余额,就能计算出账户的最终余额。
一旦跟随节点重建了数据状态,它会通过请求在该节点处于故障状态期间发生的所有客户端更新,将其预写日志(WAL)与主节点的 WAL 进行同步。在主节点共享了所有客户端更新后,跟随节点会更新自己的 WAL,并对数据执行所有的更新操作,以使数据状态与主节点及其他跟随节点保持一致。
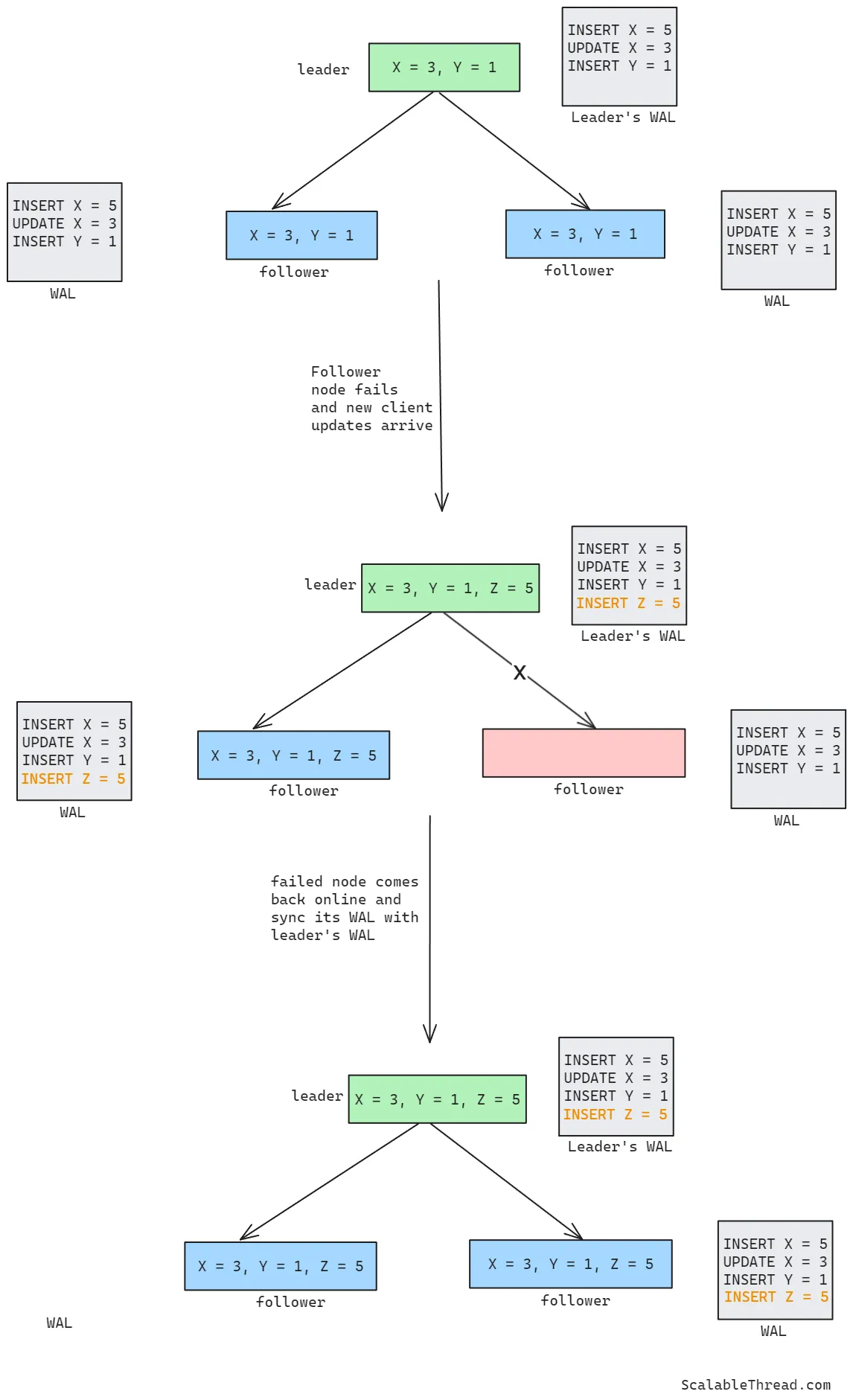
可能会出现预写日志(WAL)中有数百万条记录的情况,这会影响节点的重启时间。为了解决这个问题,数据库会定期对数据进行快照。在故障后重启时,只执行自上次快照以来追加的 WAL 记录。这大大减少了需要执行的 WAL 记录数量,从而提高了数据库状态重建的效率和性能。