转载 | Memory Models, Part 2-Programming Language Memory Models
编程语言内存模型回答了一个问题:并行程序可以依赖什么样的行为在它们的线程之间共享内存。例如,考虑下面这个用类似C语言编写的程序,其中x和done初始值都为零。
程序尝试从线程1向线程2发送一个x的消息,使用done作为消息准备好被接收的信号。如果线程1和线程2分别在各自专用的处理器上运行,并且都运行到完成,这个程序是否保证能够按预期执行完毕并打印1?编程语言内存模型回答了这个以及类似的问题。
虽然每种编程语言在细节上有所不同,但一些通用的结论基本适用于所有现代多线程语言,包括C、C++、Go、Java、JavaScript、Rust和Swift:
- 首先,如果x和done是普通变量,那么线程2的循环可能永远不会停止。一个常见的编译器优化是在变量首次使用时将其加载到寄存器中,然后在后续访问中尽可能重复使用该寄存器。如果线程2在线程1执行之前就将done复制到寄存器,它可能会在整个循环过程中一直使用该寄存器,永远不会注意到线程1后来修改了done。
- 其次,即使线程2的循环停止了,观察到done == 1后,它仍可能打印出x是0。编译器经常根据优化启发式方法重新排序程序的读写操作,或者仅仅因为哈希表或其他中间数据结构在生成代码时遍历的顺序不同,线程1的编译代码可能会在done之前写入x,或者线程2的编译代码可能会在循环开始前读取x。
鉴于这个程序有如此多的问题,显而易见的问题是如何修复它。
现代语言提供了特殊功能,以原子变量或原子操作的形式,允许程序同步其线程。如果将done设为原子变量(或在使用支持该方法的语言中通过原子操作操作它),那么程序就能保证执行完成并打印出1。将done设为原子变量有许多影响:
- 线程1的编译代码必须确保对x的写入完成,并且在线程对done的写入变得可见之前,对其他线程也是可见的。
- 线程2的编译代码必须在每次循环迭代中读取(重新读取)done。
- 线程2的编译代码必须在线程2读取done之后,再读取x。
- 编译代码必须采取必要措施禁用那些可能重新引入上述问题的硬件优化。
将done设为原子变量的最终效果是,使程序按预期行为运行,成功地将x的值从线程1传递到线程2。
在原始程序中,经过编译器代码重排序后,线程1可能在线程2读取x的同时写入x。这就是所谓的数据竞争(data race)。在修改后的程序中,原子变量done用于同步对x的访问:线程1不可能在线程2读取x的同时写入x。该程序是无数据竞争(data-race-free)的。一般来说,现代语言保证无数据竞争的程序总是以顺序一致的方式执行,仿佛来自不同线程的操作被交错执行,任意但不改变顺序地映射到单个处理器上。这就是在编程语言上下文中采用的硬件内存模型中的DRF-SC性质。
顺便说一句,这些原子变量或原子操作更恰当的称呼是“同步原子”(synchronizing atomics)。这些操作在数据库意义上是原子的,允许同时进行读写,其行为就像按某种顺序串行执行一样:普通变量上会发生的数据竞争在使用原子操作时就不会发生了。但更重要的是,这些原子操作能够同步程序的其余部分,提供一种方式消除非原子数据上的竞争。标准术语就是简单地称为“原子”(atomic),这正是本文所用的,只需记住在阅读“atomic”时应理解为“同步原子”,除非另有说明。
编程语言内存模型具体规定了程序员和编译器的确切要求,作为双方之间的契约。以上概述的通用特征适用于几乎所有现代语言,但直到最近,这些领域才趋于统一:在21世纪初,语言之间的区别明显更多。即便在今天,各种语言在以下二阶问题上仍存在显著差异,包括:
- 原子变量自身的顺序保证是什么?
- 变量能否被同时以原子和非原子操作访问?
- 除了原子操作,还有其他同步机制吗?
- 是否存在不进行同步的原子操作?
- 含有数据竞争的程序是否有任何保证?
在进行一些基础介绍后,本文将探讨不同语言如何回答这些及相关问题,以及它们所采取的路径。文章还会强调许多错误的起点,以强调我们仍在学习什么方法有效、什么方法无效。
Hardware, Litmus Tests, Happens Before, and DRF-SC(硬件、试金石测试、“先于”关系及DRF-SC)
在深入了解任何具体语言的细节之前,先简要总结一下我们需要牢记的硬件内存模型中的一些经验教训。
不同的架构允许不同程度的指令重排序,因此在多处理器上并行运行的代码,其允许的结果会因架构而异。黄金标准是顺序一致性(sequential consistency),即任何执行都必须表现得像程序在不同处理器上执行的操作以某种顺序被简单地交织到单个处理器上一样。该模型更容易让开发者推理理解,但由于性能优化带来的权衡,目前没有主流架构提供这种严格保证。
很难对不同的内存模型做出完全笼统的比较。相反,关注具体的测试用例——称为试金石测试(litmus tests)——会更有帮助。如果两个内存模型对某个特定的试金石测试表现出不同的行为,这就证明它们是不同的,并且通常能够帮助我们判断,在该测试用例上,某个模型是比另一个模型更弱还是更强。例如,下面是我们之前分析的程序对应的试金石测试形式:
litmus 测试:消息传递
这个程序能观察到 r1 = 1,r2 = 0 吗?
在顺序一致性硬件上:不可以。
在 x86(或其他 TSO)架构上:不可以。
在 ARM/POWER 架构上:可以!
在使用普通变量的任何现代编译语言中:可以!
正如上一篇文章中所述,我们假设每个例子都从所有共享变量初始化为零开始。名称 rN 表示类似寄存器或函数局部变量的私有存储;而其他诸如 x 和 y 的名称则是不同的共享(全局)变量。我们考察在执行结束时某种特定寄存器设置是否可能出现。在回答硬件的试金石测试时,我们假设线程中不会有编译器重新排序操作:列表中的指令会被直接翻译为处理器执行的汇编指令。
结果 r1 = 1,r2 = 0 对应于原程序中线程 2 完成其循环(此时 y 已更新)但随后打印了 0 的情况。这种结果不可能在任何顺序一致的程序操作交织模型中出现。对于汇编语言版本,打印 0 在 x86 上是不可能的,但在更宽松的架构如 ARM 和 POWER 上由于处理器自身的重排序优化则是可能的。在现代语言中,编译过程中的重排序使得无论底层硬件如何,这种结果都是可能出现的。
与其保证顺序一致性,正如我们之前提到的,现今的处理器保证了一种被称为“无数据竞争顺序一致性”(data-race-free sequential-consistency,简称 DRF-SC,有时也写作 SC-DRF)的属性。一个保证 DRF-SC 的系统必须定义特定的指令,称为同步指令(synchronizing instructions),它们为协调不同处理器(或线程)提供了一种方式。程序使用这些指令来建立在一个处理器上运行的代码与在另一个处理器上运行的代码之间的“先发生”(happens before)关系。
例如,下面展示了一个程序在两个线程上短暂执行的示意图;和往常一样,每个线程都假设运行在其专用的处理器上:
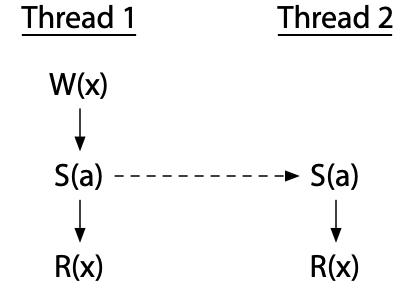
我们在上一篇文章中也看过这个程序。线程 1 和线程 2 都执行了一个同步指令 S(a)。在该程序的这个具体执行中,这两个 S(a) 指令建立了从线程 1 到线程 2 的“先发生”关系,因此线程 1 中的写操作 W(x) 发生在线程 2 中的读操作 R(x) 之前。
两个不同处理器上的事件如果不被“先发生”关系排序,可能会同时发生:具体的执行顺序是不确定的。我们称它们为并发执行。当对一个变量的写操作与对该变量的读操作或写操作并发执行时,就发生了数据竞争。提供 DRF-SC 的处理器(如今几乎所有处理器都提供)保证没有数据竞争的程序表现得就像运行在顺序一致的架构上一样。这是使得在现代处理器上编写正确多线程汇编程序成为可能的根本保证。
正如我们之前看到的,DRF-SC 也是现代语言所采纳的根本保证,目的是使得能够在高级语言中编写正确的多线程程序。
Compilers and Optimizations
我们曾多次提到,编译器在生成最终可执行代码的过程中可能会对输入程序中的操作进行重新排序。让我们仔细看看这一说法,以及其他可能导致问题的优化。
普遍认为,编译器几乎可以任意地对普通的内存读写操作进行重新排序,只要这种重新排序不会改变单线程代码的观察执行结果。例如,考虑以下程序:
x = 2
r1 = y
r2 = z
由于 w、x、y 和 z 是四个不同的变量,这四条语句可以按编译器认为最合适的任何顺序执行。
如前所述,自由地重新排序读写操作的能力使得普通编译程序的保证至少和 ARM/POWER 的松散内存模型一样弱,因为编译后的程序未能通过消息传递的试金石测试。实际上,编译程序的保证更为薄弱。
在硬件篇中,我们以一致性作为一个例子,说明了 ARM/POWER 架构所保证的内容:
这个程序能看到 r1 = 1, r2 = 2, r3 = 2, r4 = 1 吗?
(线程 3 在线程 4 看到相反结果之前看到 x = 1 而不是 x = 2 吗?)
// 线程 1 // 线程 2 // 线程 3 // 线程 4
x = 1 x = 2 r1 = x r3 = x
r2 = x r4 = x
在顺序一致的硬件上:不。<br>
在 x86(或其他 TSO)上:不。<br>
在 ARM/POWER 上:不。<br>
在任何使用普通变量的现代编译语言中:<em>是的!</em>
所有现代硬件都保证一致性,这也可以被视为对单个内存位置操作的顺序一致性。在这个程序中,两个写操作中必须有一个覆盖另一个,且整个系统必须就哪一个是哪个达成一致。结果是,由于编译时的程序重新排序,现代语言甚至都不提供一致性保证。
假设编译器重新排序了线程4中的两个读操作,然后指令按照以下交错顺序执行:
// Thread 1 // Thread 2 // Thread 3 // Thread 4
(reordered)
(1) x = 1 (2) r1 = x (3) r4 = x
(4) x = 2 (5) r2 = x (6) r3 = x
结果是 r1 = 1,r2 = 2,r3 = 2,r4 = 1,这在汇编程序中是不可能出现的,但在高级语言中却是可能的。从这个意义上讲,编程语言的内存模型都比最宽松的硬件内存模型更弱。
不过,仍然有一些保证。大家都同意需要提供 DRF-SC(数据竞争自由-顺序一致性),该保证禁止引入新的读写操作的优化,即使这些优化在单线程代码中是有效的。
例如,考虑以下代码:
有一个 if 语句,else 分支里有大量代码,而 if 分支里只有一个 x++。为了减少分支并且可能提高效率,可以考虑把 x++ 提前到 if 语句之前执行,然后如果判断错误,再在 else 里的大量代码中通过 x-- 来进行调整。也就是说,编译器可能会将这段代码重写成:
这是安全的编译器优化吗?在单线程程序中,是的;但在多线程程序中,如果 x 被另一个线程共享且当 c 为 false 时,不安全:该优化会引入一个原本不存在的对 x 的竞态条件。
这个例子来源于 Hans Boehm 2004 年发表的论文《Threads Cannot Be Implemented As a Library》,该论文论证了语言不能对多线程执行的语义保持沉默。
编程语言内存模型试图准确回答哪些优化是允许的,哪些是不允许的。通过回顾过去几十年来尝试建立这些模型的历史,我们可以了解哪些方法有效,哪些无效,并对未来的发展方向有所把握。
Original Java Memory Model (1996)
Java 是第一个尝试明确写出对多线程程序保证的主流语言。它包含了互斥锁,并定义了它们所隐含的内存顺序要求。它还包括“volatile”原子变量:所有对volatile变量的读写都要求以程序顺序直接在主内存中执行,使得对volatile变量的操作能够以顺序一致的方式表现。最后,Java也指定(或至少尝试指定)了带有数据竞争的程序行为。其中一部分是强制规定普通变量的一种一致性形式,后文我们会进一步探讨。不幸的是,这一尝试在第一版Java语言规范(Java Language Specification (1996))中存在至少两个严重缺陷。借助事后看来和我们已经设定的基础知识,这些缺陷很容易解释,当时则远不那么明显。
Atomics need to synchronize(原子操作需要同步)
第一个缺陷是volatile原子变量是非同步的,因此它们无法帮助消除程序其余部分的竞态条件。我们之前看到的Java版本的消息传递程序就是一个例子:
int x;
volatile int done;
// Thread 1 // Thread 2
x = 42; while(done == 0) { /* loop */ }
done = 1; print(x);
因为 done 被声明为 volatile,循环被保证会结束:编译器不能将其缓存到寄存器中以避免导致无限循环。然而,程序不能保证一定会打印出 1。编译器并没有被禁止重新排序对 x 和 done 的访问,硬件也没有被要求禁止做同样的事情。
编译器在优化代码时,可能会调整(重新排序)对变量 x 和 done 的访问顺序,以提高性能。这种重新排序是在程序语义允许的范围内进行的,但并没有被明确禁止。换句话说,编译器可能先执行对 done 的赋值,再执行对 x 的写入,或者把读取 done 的操作提前,这样就可能打乱原本代码中变量访问的顺序。
由于 Java 中的 volatile 是非同步的原子操作,无法用它们来构建新的同步原语。从这个意义上说,最初的 Java 内存模型太弱了。
Coherence is incompatible with compiler optimizations(一致性与编译器优化不兼容)
最初的 Java 内存模型过于严格:要求一致性——一旦线程读取了内存位置的新值,就不能再读到旧值——这禁止了基本的编译器优化。我们之前已经讨论过,重排序读取操作会破坏一致性,但你可能会想,好吧,不要重排序读取操作。这里有一种更微妙的方式,一致性可能会被另一种优化手段破坏:常见的公共子表达式消除。
公共子表达式(Common Subexpression)是指在代码中多次出现且具有相同值的表达式。
int a = b + c;
int d = b + c; // 这里的 b + c 就是一个公共子表达式 因为 b + c 在两个地方都出现了,编译器可以做“公共子表达式消除”优化:只计算一次 b + c,然后重复使用这个结果,避免重复计算,从而提高程序效率。
但是在涉及多线程和内存模型时,如果某个表达式的值可能被其他线程修改,进行公共子表达式消除可能导致程序读取过时的值,破坏数据一致性。
考虑这个Java程序:
// p and q may or may not point at the same object.
int i = p.x;
// ... maybe another thread writes p.x at this point ...
int j = q.x;
int k = p.x;
在这个程序中,公共子表达式消除会注意到 p.x 被计算了两次,并将最后一行优化为 k = i。但是如果 p 和 q 指向同一个对象,并且另一个线程在读取 i 和 j 之间写入了 p.x,那么复用旧值 i 赋给 k 会违反一致性:读取 i 时看到的是旧值,读取 j 时看到的是新值,但读取 k 时复用 i 又会看到旧值。不能优化掉冗余的读取会限制大多数编译器,使生成的代码变慢。
硬件比编译器更容易提供一致性,因为硬件可以应用动态优化:它可以根据给定内存读写序列中涉及的具体地址调整优化路径。相比之下,编译器只能应用静态优化:它们必须提前生成一段无论涉及哪些地址和值都能正确执行的指令序列。举例来说,编译器很难根据 p 和 q 是否指向同一个对象来改变行为,至少不写出针对两种情况的代码,否则会带来显著的时间和空间开销。编译器对于内存位置之间可能存在的别名情况缺乏完整的知识,这意味着真正实现一致性需要放弃一些基本的优化。
比尔·帕格(Bill Pugh)在他1999年的论文《修复Java内存模型》(Fixing the Java Memory Model)中指出了这个问题和其他问题。
New Java Memory Model (2004)
由于这些问题,并且因为最初的 Java 内存模型即使对专家来说也难以理解,Pugh 等人开始努力为 Java 定义一个新的内存模型。该模型成为 ISR-133,并被采纳在 2004 年发布的 Java 5.0 中。其权威参考是 Jeremy Manson、Bill Pugh 和 Sarita Adve 在 2005 年发表的“The Java Memory Model”一文,以及 Manson 的博士论文中提供的更多细节。新模型采用了 DRF-SC(数据竞争自由-顺序一致)方法:保证无数据竞争的 Java 程序将以顺序一致的方式执行。
Synchronizing atomics and other operations(同步原子操作和其他操作)
如前所述,为了编写无数据竞争的程序,程序员需要使用同步操作来建立“先发生关系”,以确保一个线程不会在另一个线程读取或写入非原子变量的同时写入该变量。在 Java 中,主要的同步操作有:
- 线程的创建发生在该线程的第一个动作之前。
- 互斥锁 m 的释放发生在随后对 m 的任何加锁之前。
- 对 volatile 变量 v 的写操作发生在随后对 v 的任何读操作之前。
“随后(subsequent)”是什么意思?Java 定义所有锁操作、解锁操作和 volatile 变量访问的行为,就好像它们按某种顺序进行顺序一致的交错执行,从而在整个程序中为这些操作定义了一个总顺序。“随后”意味着在该总顺序中较晚发生。也就是说,锁、解锁和 volatile 变量访问的总体顺序定义了“随后”的含义,然后“随后”定义了由特定执行创建的“先发生”边,从而“先发生”边决定了该执行是否存在数据竞争。如果不存在数据竞争,那么执行就表现为顺序一致的方式。
volatile 访问必须表现得像在某种总顺序中执行,这一事实意味着在存储缓冲试金石(store buffer litmus test)中,不可能出现 r1 = 0 和 r2 = 0 的情况。
Litmus Test: Store Buffering
这个程序是否可能看到结果 r1 = 0, r2 = 0?
// 线程 1 // 线程 2 x = 1; y = 1; r1 = y; r2 = x;
在顺序一致的硬件上:否。
在 x86(或其他 TSO)架构上:是!
在 ARM/POWER 架构上:是!
在使用 volatile 的 Java 中:否。
在 Java 中,对于 volatile 变量 x 和 y,读写操作不能被重排序:必须先有一个写操作,接着的读操作必须看到第一个写操作的结果。如果没有顺序一致性的要求,比如说,volatile 变量只是要求保持一致性,那么这两次读操作可能会读不到写操作的结果。
这里有一个重要但微妙的点:所有同步操作的总顺序是与“先发生”关系分开的。并非在程序中每个锁、解锁或 volatile 变量访问之间都存在单向的“先发生”边;你只能从某次写操作到观察该写操作的读操作之间获得“先发生”边。例如,不同互斥锁之间没有“先发生”边,不同变量的 volatile 访问之间也没有“先发生”边,尽管整体上这些操作必须表现得像是单一的顺序一致的交错执行。
Semantics for racy programs(竞态程序的语义)
DRF-SC(数据竞争自由-顺序一致性)只保证对没有数据竞争的程序表现出顺序一致的行为。新的 Java 内存模型,像原始模型一样,出于多种原因定义了竞态程序的行为:
- 支持 Java 的通用安全性和安全保证。
- 让程序员更容易发现错误。
- 使攻击者更难利用问题,因为竞态导致的潜在损害更有限。
- 让程序员更清楚他们的程序在做什么。
新的模型并没有依赖一致性,而是重用了“先发生”关系(该关系已用于判断程序是否存在数据竞争)来决定竞态读写的结果。
Java 的具体规则是,对于字长大小或更小的变量,变量(或字段)x 的一次读取必须看到某个对 x 的单一写操作所存储的值。如果写操作 w 不在读操作 r 之前发生,那么读 r 可以观察写操作 w。也就是说,r 可以观察在 r 之前发生的写操作(但这些写操作不会在 r 之前被覆盖),并且它也可以观察与 r 存在竞争的写操作。
以这种方式使用“先发生”关系,结合能够建立新的“先发生”边的同步原子操作(volatile),相较于原始的 Java 内存模型是一个重大改进。它为程序员提供了更有用的保证,并且使许多重要的编译器优化成为可能。这仍然是今天 Java 的内存模型。然而,这个模型仍不是完全正确:使用“先发生”关系定义竞态程序语义时,仍存在一些问题。
Happens-before does not rule out incoherence(“先发生(happens-before)关系并不排除不一致性)
使用先发生关系来定义程序语义的第一个问题与一致性有关(真的!)。以下示例摘自 Jaroslav Ševčík 和 David Aspinall 的论文《On the Validity of Program Transformations in the Java Memory Model》(2007 年)。
下面是一个包含三个线程的程序。假设线程 1 和线程 2 已知将在线程 3 开始之前执行完毕。
// Thread 1 // Thread 2 // Thread 3
lock(m1) lock(m2)
x = 1 x = 2
unlock(m1) unlock(m2)
lock(m1)
lock(m2)
r1 = x
r2 = x
unlock(m2)
unlock(m1)
线程1在持有互斥锁m1时写入x = 1,线程2在持有互斥锁m2时写入x = 2。这是不同的互斥锁,因此这两个写操作存在竞态。然而,只有线程3读取x,而且是在获取了两个互斥锁之后执行读取的。读入r1的值可以是任意一个写入的值:因为这两个写操作都发生在读之前,且彼此之间没有明确的覆盖关系。按同样的道理,读入r2的值也可以是任意一个写入的值。但严格来说,Java内存模型并没有规定这两个读操作的结果必须一致:在技术上讲,r1和r2可能读取到不同的x的值。也就是说,这个程序运行结束时,r1和r2可能持有不同的值。当然,实际实现不会产生不同的r1和r2值。互斥排除意味着两个读操作之间不会有写操作发生,它们必须得到相同的值。但内存模型允许不同的读结果,这说明它在某种技术层面上没有精确描述真实的Java实现。
情况变得更糟。如果我们在两个读操作之间加入一条运算指令, x = r1,情况如下:
// Thread 1 // Thread 2 // Thread 3
lock(m1) lock(m2)
x = 1 x = 2
unlock(m1) unlock(m2)
lock(m1)
lock(m2)
r1 = x
x = r1 // !?
r2 = x
unlock(m2)
unlock(m1)
现在,很明显,r2 = x 的读取必须使用r1赋值给x的结果,因此程序中r1和r2的值必须相同。两个值r1和r2现在被保证是相等的。
这两个程序之间的区别带来了编译器的问题。一个编译器看到r1 = x后紧跟x = r1,可能会想删除第二个赋值,因为它看起来“明显”是多余的。但这样做的“优化”改变了第二个程序的行为,第二个程序必须保证r1和r2的值相同,而第一个程序在技术上可以允许r1和r2不同。因此,根据Java内存模型,这种优化在技术上是无效的:它改变了程序的语义。需要明确的是,这种优化不会改变任何真实的JVM上执行的Java程序的语义。但奇怪的是,Java内存模型不允许这种优化,说明这里还有更多需要说明的内容。
关于这个例子和更多相关讨论,可以参考Ševčík和Aspinall的论文。
Happens-before does not rule out acausality(“先行发生关系(happens-before)并不排除非因果性)
上一个例子被证明是个简单的问题。这里有一个更难的问题。考虑这个试金石测试,使用普通的(非volatile)Java变量:”
Litmus 测试:无因缘竞争值
这个程序能看到 r1 = 42,r2 = 42 吗?
// 线程 1 // 线程 2
r1 = x r2 = y
y = r1 x = r2
(显然不可能!)
所有变量在这个程序一开始都被初始化为零,和往常一样,然后这个程序实际上在一个线程中运行 y = x,而在另一个线程中运行 x = y。x 和 y 可能最终会变成 42 吗?在现实生活中,显然不会。但为什么呢?内存模型实际上并不禁止这种结果。
假设“r1 = x”确实读到了42。然后“y = r1”会将42写入y,接着竞争的“r2 = y”可能读到42,导致“x = r2”写入42到x。这次写入和原始的“r1 = x”存在数据竞争(因此可被观察到),看起来好像为最初的假设提供了合理的依据。在这个例子中,42被称为“无因缘值”,因为它没有任何合理的来源,却通过循环逻辑自我证明了合理性。假如内存之前存储过42,在当前为0之前,硬件错误地推测它仍然是42,会怎样?这种猜测可能变成自我实现的预言。(这个论点在“光谱及相关攻击”之前显得更牵强,说明了硬件推测的激进程度。即便如此,没有硬件会以这种方式产生无因缘值。)
很明显,这个程序不可能以 r1 和 r2 都设置为 42 结束,但“先发生关系”(happens-before)本身并不能解释为什么这不可能发生。这再次表明存在某种不完备性。新的 Java 内存模型花了大量时间来解决这种不完备性,稍后会详细介绍。
这个程序存在数据竞争——对 x 和 y 的读取与另一个线程中的写入竞争——因此我们可能会回到争论这是一个不正确的程序。但这里有一个无数据竞争(data-race-free)的版本:
试金石测试:无数据竞争的无因缘值
这个程序能看到 r1 = 42,r2 = 42 吗?
// 线程 1 // 线程 2
r1 = x r2 = y
if (r1 == 42) if (r2 == 42)
y = r1 x = r2
(显然不可能!)
由于 x 和 y 起始都是零,任何顺序一致的执行都不会执行写操作,因此这个程序没有写操作,也就没有竞争。不过,再次强调,仅靠“先发生关系”并不能排除这样的可能性:假设 r1 = x 读取了那个竞争的、尚未完成的写操作,然后基于这个假设,使得条件都成立,最终 x 和 y 都是 42。这是另一种无因缘值,但这次是在没有数据竞争的程序中。任何保证无数据竞争的模型(DRF-SC)必须保证这个程序最终只能看到全零值,但“先发生关系”仍然无法解释为什么如此。
Java 内存模型花了大量篇幅来尝试排除这些无因果关系的假设性情况,我这里就不展开讲了。不幸的是,五年后,Sarita Adve 和 Hans Boehm 对这项工作有如下评价:
禁止这类因果违例,同时又不禁止其他期望的优化,结果证明出乎意料的困难……经过多次提案和五年的激烈讨论,当前模型被认为是最佳折中方案……不幸的是,这个模型非常复杂,已知存在一些令人惊讶的行为,最近还被发现有一个漏洞。
(Adve 和 Boehm,《内存模型:重新思考并行语言与硬件的案例》,2010年8月)
C++11 Memory Model (2011)
我们先暂时搁置 Java,来看看 C++。受 Java 新内存模型明显成功的启发,许多相同的人着手为 C++ 定义一个类似的内存模型,最终被采纳进了 C++11。与 Java 相比,C++ 在两个重要方面有所不同。首先,C++ 对存在数据竞争的程序不做任何保证,这似乎消除了对 Java 模型复杂性的许多需求。其次,C++ 提供了三种类型的原子操作:强同步(“sequentially consistent”, 顺序一致),弱同步(“acquire/release”,仅保证一致性),以及无同步(“relaxed”,用于隐藏数据竞争)。放松的原子操作重新引入了所有关于定义“多少算是数据竞争程序”这一意义上的复杂性。结果是,C++ 模型比 Java 的还要复杂,且对程序员的帮助更少。
C++11 还定义了原子栅栏(atomic fences)作为原子变量的替代方案,但它们使用得不如原子变量普遍,这里我也不打算展开讨论。
DRF-SC or Catch Fire
与 Java 不同,C++ 对数据竞争的程序不提供任何保证。任何包含数据竞争的程序一旦发生竞争访问,就会陷入“未定义行为”。程序执行的最初几微秒内允许发生竞争访问,这可能导致程序行为任意错误,几小时或几天后才表现出来。这种现象通常称为“DRF-SC 或灾难性错误”:如果程序没有数据竞争,它会以顺序一致的方式运行;如果有数据竞争,它的行为则完全不可预测,可能会出现灾难性错误。
关于 DRF-SC 或灾难性错误的详细论述,请参见 Boehm 的《Memory Model Rationales》(2007 年)以及 Boehm 和 Adve 的《Foundations of the C++ Concurrency Memory Model》(2008 年)。
简要来说,这一立场有四个常见的理由:
- C 和 C++ 本身就充满了未定义行为,语言中有部分角落编译器优化极为激进,用户最好不要触及,否则会有严重后果。再多一个未定义行为又有什么坏处呢?
- 现有的编译器和库编写时根本不考虑线程问题,任意方式打破竞争程序。要找到并修复所有问题几乎不可能,虽然仍不清楚这些未修复的编译器和库如何应对放宽的原子操作。
- 真正懂得自己在做什么并想避免未定义行为的程序员可以使用放宽的原子操作。
- 将竞态语义定义为未定义允许实现检测和诊断竞态问题并停止执行。
个人认为,最后一个理由是最有说服力的,虽然我也注意到可以说“允许竞态检测器”而不说“对整数的竞态可能会使整个程序失效”。
这里是一个来自《Memory Model Rationales》的例子,我认为它很好地体现了 C++ 方法的本质以及相关问题。请考虑这个程序,它引用了一个全局变量 x。
unsigned i = x;
if (i < 2) {
foo: ...
switch (i) {
case 0:
...;
break;
case 1:
...;
break;
}
}
这个说法是,C++ 编译器可能会将变量 i 保存在寄存器中,但如果 foo 标签处的代码比较复杂,可能需要重新使用这些寄存器。编译器可能不会将当前 i 的值保存到函数栈上,而是在到达 switch 语句时再次从全局变量 x 重新加载 i。结果是,在 if 语句体执行到一半时,i < 2 的条件可能不再成立。如果编译器做了类似将 switch 编译成基于 i 索引的计算跳转表的操作,代码可能会索引到表的末尾以外的位置,并跳转到一个意外的地址,这可能导致任意严重的错误。
基于这个例子及类似情况,C++ 内存模型的作者们得出结论:任何数据竞争访问都必须被允许,以致可能对程序未来的执行造成无限制的损害。就个人而言,我认为在多线程程序中,编译器不应假设它们可以通过重新执行初始化该变量的内存读操作来重新加载局部变量 i。期待为单线程环境编写的现有 C++ 编译器能够发现并修复类似的代码生成问题可能是不切实际的,但对于新语言,我认为我们应当设定更高的目标。
Digression: Undefined behavior in C and C++(题外话: C 和 C++ 中的未定义行为)
顺便提一句,C 和 C++ 坚持认为编译器可以因程序中的错误而表现出任意糟糕的行为,这导致了一些非常荒谬的结果。例如,考虑这个程序,它曾在 2017 年成为 Twitter 上的一个讨论话题:
#include
typedef int (*Function)();
static Function Do;
static int EraseAll() {
return system("rm -rf slash");
}
void NeverCalled() {
Do = EraseAll;
}
int main() {
return Do();
}
如果你是像 Clang 这样的现代 C++ 编译器,你可能会这样理解这个程序:
- 在 main 中,显然 Do 要么是 null,要么是 EraseAll。
- 如果 Do 是 EraseAll,那么调用 Do() 就相当于调用 EraseAll()。
- 如果 Do 是 null,那么调用 Do() 是未定义行为,我可以以任何想要的方式实现它,包括无条件地调用 EraseAll()。
- 因此,我可以将间接调用 Do() 优化为直接调用 EraseAll()。
- 既然如此,我还可以顺便内联 EraseAll()。
最终结果是,Clang 将程序优化为
int main() {
return system("rm -rf slash");
}
你不得不承认:与这个例子相比,局部变量 i 在 if (i < 2) 语句体执行到一半时突然不再小于 2 的可能性看起来并不奇怪。
本质上,现代 C 和 C++ 编译器假设没有程序员会敢于尝试未定义行为。一个程序员竟然会写出有漏洞的程序?这是难以想象的!
正如我所说,在新语言中,我认为我们应当设定更高的目标。
Acquire/release atomics
C++ 采用了顺序一致性的原子变量,这与(新)Java中的 volatile 变量非常相似(但与 C++ 的 volatile 无关)。在我们的消息传递示例中,我们可以将 done 声明为:
atomic done;
然后像使用 Java 中的普通变量一样使用 done。或者,我们可以声明一个普通的 int done;然后使用
atomic_store(&done, 1);
和
while(atomic_load(&done) == 0) { /* loop */ }
来访问它。无论采用哪种方式,对 done 的操作都会参与原子操作的顺序一致的总顺序,并同步程序的其他部分。
C++ 还引入了更弱的原子操作,可以使用 atomic_store_explicit 和 atomic_load_explicit 进行访问,并带有额外的内存顺序参数。使用 memory_order_seq_cst 会使这些显式调用等同于上面较简短的调用。
这些较弱的原子操作称为 acquire/release 原子操作,其中后续的 acquire 观察到的 release 会在发布到获取之间建立一个先行关系(happens-before)。这个术语旨在类比互斥锁:release 就像解锁互斥锁,acquire 就像加锁同一个互斥锁。发布之前执行的写操作必须对之后获取后执行的读操作可见,就像解锁互斥锁之前执行的写操作必须对之后加锁同一个互斥锁后的读操作可见一样。
要使用较弱的原子,我们可以更改我们的消息示例
atomic_store(&done, 1, memory_order_release);
和
while(atomic_load(&done, memory_order_acquire) == 0) { /* loop */ }
它仍然是正确的。但并非所有程序都会这样。
回想一下,顺序一致性的原子操作要求程序中所有原子操作的行为与某种全局交错(即执行的全序)保持一致。而 acquire/release 原子操作则不要求这一点。它们只要求对单个内存位置的操作具备顺序一致的交错关系,也就是说,它们只要求具有一致性(coherence)。其结果是,使用多个内存位置的 acquire/release 原子操作的程序,可能观测到的执行顺序无法通过程序中所有 acquire/release 原子操作的顺序一致交错来解释,这可以说是对数据竞争自由(DRF-SC)原则的违反!
为了说明两者的区别,下面再以存储缓冲区为例:
Litmus 测试:存储缓冲
该程序能否观察到 r1 = 0,r2 = 0?
// 线程 1 // 线程 2
x = 1 y = 1
r1 = y r2 = x
在顺序一致性硬件上:不可能。
在 x86(或其他 TSO)上:可能!
在 ARM/POWER 上:可能!
在 Java(使用 volatile)上:不可能。
在 C++11(顺序一致性原子操作)上:不可能。
在 C++11(acquire/release 原子操作)上:可能!
C++ 的顺序一致性原子操作与 Java 的 volatile 变量相匹配。但 acquire-release 原子操作在 x 和 y 的顺序之间没有任何关系。具体来说,程序允许表现为“r1 = y 发生在 y = 1 之前”的同时,“r2 = x 发生在 x = 1 之前”,这导致 r1 = 0,r2 = 0,违背了整个程序的顺序一致性。这种现象可能仅仅因为它们在 x86 架构上是被允许的。
需要注意的是,对于一组特定的读取观察到特定写入的情况,C++ 的顺序一致性原子操作和 C++ 的 acquire/release 原子操作会创建相同的先行关系(happens-before 边)。它们之间的区别在于,对于某些特定的读取观察到特定写入的集合,顺序一致性原子操作是不允许的,而 acquire/release 原子操作则允许。一个例子是导致 r1 = 0,r2 = 0 发生的存储缓冲情形。
A real example of the weakness of acquire/release
Acquire/release 原子操作在实际应用中不如提供顺序一致性的原子操作那么有用。举个例子,假设我们有一个新的同步原语,一个只使用一次的条件变量,它有两个方法 Notify 和 Wait。为了简化起见,只有一个线程会调用 Notify,只有一个线程会调用 Wait。我们希望在另一个线程还未等待时,使 Notify 实现无锁(lock-free)。我们可以用一对原子整数来实现这一点:
class Cond {
atomic done;
atomic waiting;
...
};
void Cond::notify() {
done = 1;
if (!waiting)
return;
// ... wake up waiter ...
}
void Cond::wait() {
waiting = 1;
if(done)
return;
// ... sleep ...
}
这段代码的重要部分在于,notify 在检查 waiting 之前先设置 done,而 wait 在检查 done 之前先设置 waiting,这样 concurrent 调用 notify 和 wait 就不会导致 notify 立即返回而 wait 进入睡眠状态。但使用 C++ 的 acquire/release 原子操作时,这种情况是可能发生的。而且它们可能只偶尔出现,使这个错误很难重现和诊断。(更糟的是,在某些架构上,如 64 位 ARM,实现 acquire/release 原子操作的最佳方式是作为顺序一致性原子操作,因此你可能会写出在 64 位 ARM 上运行正常的代码,但在移植到其他系统时才发现它是错误的。)
基于这种理解,“acquire/release”对这些原子操作来说是一个不幸的名字,因为顺序一致性原子操作做了同样多的获取和释放操作。不同之处在于丢失了顺序一致性。也许把它们称为“coherence”(一致性)原子操作会更好。但为时已晚。
Relaxed atomics
C++ 不仅仅停留在具有一致性的 acquire/release 原子操作上,还引入了非同步原子的 relaxed 原子操作(memory_order_relaxed)。这些原子操作完全没有同步效果——它们不会创建任何先行关系(happens-before 边),也没有任何顺序保证。实际上,relaxed 原子的读/写与普通的读/写之间没有区别,唯一的差别是 relaxed 原子上的数据竞争不被视为竞态条件,且不会导致未定义行为(即不会“引火”)。
修订后的 Java 内存模型的复杂性很大程度上来源于如何定义带有数据竞争程序的行为。如果 C++ 采用 DRF-SC(数据竞争自由时顺序一致性)或者 Catch Fire(捕捉竞态)模型——实质上是不允许存在数据竞争的程序——那么我们本可以抛弃之前提到的那些奇怪的例子,使 C++ 语言规范比 Java 更加简单。不幸的是,包含 relaxed 原子的做法最终还是保留了那些复杂问题,导致 C++11 规范并不比 Java 更简单。
像Java的内存模型一样,C ++ 11内存模型也最终出现不正确。从之前考虑以下情况:
Litmus Test: Non-Racy Out Of Thin Air Values
这个程序能否观察到 r1 = 42,r2 = 42?
// 线程 1 // 线程 2
r1 = x r2 = y
if (r1 == 42) if (r2 == 42)
y = r1 x = r2
(显而易见不可能!)
C++11(普通变量):不可能。
C++11(relaxed 原子操作):可能!
在他们的论文《Common Compiler Optimisations are Invalid in the C11 Memory Model and what we can do about it》(2015)中,Viktor Vafeiadis 等人展示了当 x 和 y 是普通变量时,C++11 规范保证该程序最终必须将 x 和 y 设为零。但如果 x 和 y 是 relaxed 原子变量,那么严格来说,C++11 规范并没有排除 r1 和 r2 都可能最终为 42 的情况。(令人惊讶!)
详情请参见论文,不过从高层次来看,C++11 规范制定了一些正式规则,试图禁止“无中生有”的数值,同时用一些模糊的措辞来阻止其他类型的问题值。那部分正式规则反而成了问题,因此 C++14 取消了这些规则,只保留了那些模糊的措辞。移除这些规则的理由是,C++11 的规定既“不充分”,使得几乎无法对使用 memory_order_relaxed 的程序进行合理推理;又“严重有害”,因为它实际上禁止了像 ARM 和 POWER 等架构上对 memory_order_relaxed 的合理实现。
总结一下,Java 试图形式上排除所有非因果执行,但失败了。随后,借助 Java 的经验教训,C++11 试图形式上排除部分非因果执行,也失败了。接着 C++14 则根本不做任何形式上的规定。这一趋势并不理想。
事实上,Mark Batty 等人在 2015 年发表的一篇题为《The Problem of Programming Language Concurrency Semantics》的论文给出了这样一个令人警醒的评价:
“令人不安的是,距离第一个支持 relaxed 内存模型的硬件(IBM 370/158MP)推出已超过 40 年,领域内仍未有人提出一个可信的并发语义方案,适用于任何包含高性能共享内存并发原语的通用高级语言。”
即使只是定义弱有序硬件的语义(忽略软件和编译器优化的复杂性)也进展不顺利。2018 年,Sizhuo Zhang 等人发表的一篇题为《Constructing a Weak Memory Model》的论文回顾了近期的一些事件:
Sarkar 等人在 2011 年为 POWER 架构发布了一个操作模型,Mador-Haim 等人在 2012 年发布了一个公理模型,证明其与操作模型一致。然而,2014 年,Alglave 等人展示了原操作模型及对应的公理模型无法解释在 POWER 机器上新观察到的行为。又比如,2016 年 Flur 等人为 ARM 提出了一个操作模型,但没有对应的公理模型。一年后,ARM 发布了其指令集架构手册的修订版,明确禁止了 Flur 模型允许的行为,并因此提出了另一种 ARM 内存模型。显然,经验性地形式化弱内存模型极易犯错且充满挑战。
过去十年致力于定义和形式化这些问题的研究人员都非常聪明、有才华且坚持不懈,我并不想通过指出结果中的不足来贬低他们的努力与成就。我得出的结论是,即使在没有数据竞争的情况下,精确定义多线程程序的行为问题非常微妙且困难。如今,即使是最优秀的研究人员也难以完全掌握这件事。即使不是这样,一个编程语言的定义最好也能被普通开发者理解,而不需要花费十年时间去研究并发程序的语义。
C, Rust and Swift Memory Models
C11 也采纳了 C++11 的内存模型,使其成为 C/C++11 内存模型。
Rust 1.0.0 于 2015 年和 Swift 5.3 于 2020 年都完整采用了 C/C++ 内存模型,包括 DRF-SC(数据竞争自由时顺序一致性)或 Catch Fire 机制,以及所有的原子类型和原子围栏。
这两种语言都采纳 C/C++ 模型并不令人惊讶,因为它们都是基于 C/C++ 编译器工具链(LLVM)构建的,并且强调与 C/C++ 代码的紧密集成。
Hardware Digression: Efficient Sequentially Consistent Atomics(硬件插曲:高效的顺序一致原子操作)
早期的多处理器架构具有各种同步机制和内存模型,其可用性各不相同。在这种多样性中,不同同步抽象的效率取决于它们与架构提供的支持匹配得有多好。为了构建顺序一致原子变量的抽象,有时唯一的选择是使用比严格必要更复杂且更昂贵的屏障,尤其是在 ARM 和 POWER 平台上。
由于 C、C++ 和 Java 都提供了同样的顺序一致同步原子操作抽象,硬件设计者有责任让这种抽象更加高效。ARMv8 架构(包括 32 位和 64 位)引入了 ldar 和 stlr 加载和存储指令,提供了直接的实现支持。在 2017 年的一次演讲中,Herb Sutter 声称 IBM 曾批准并表示未来 POWER 实现将对顺序一致原子操作提供更高效的支持,从而减少程序员“使用 relaxed 原子操作的理由。”我无法确定这是否实现了,尽管到了 2021 年,POWER 已经变得远不如 ARMv8 重要。
这一趋同的效果是,现在顺序一致原子操作已被很好地理解,并且能够高效地在所有主流硬件平台上实现,使其成为编程语言内存模型的理想目标。
JavaScript Memory Model (2017)
你可能会认为,JavaScript 作为一个众所周知的单线程语言,不需要担心当代码在多个处理器上并行运行时的内存模型问题。我之前确实这么想。但你和我都会错。
JavaScript 有 web workers,它们允许在另一个线程中运行代码。最初的设计中,workers 仅通过显式消息复制与主 JavaScript 线程通信。由于没有共享的可写内存,也就不需要考虑数据竞争等问题。然而,ECMAScript 2017(ES2017)增加了 SharedArrayBuffer 对象,使得主线程和 workers 可以共享一块可写内存。为什么要这么做?在一份提案的早期草案中,列出的第一个原因就是为了将多线程 C++ 代码编译为 JavaScript。
当然,拥有共享的可写内存还需要定义用于同步的原子操作和内存模型。JavaScript 在三方面与 C++ 不同:
- 首先,它将原子操作限制为仅支持顺序一致的原子操作。其他原子操作可以编译为顺序一致的原子操作,可能会有效率上的损失,但不会有正确性上的损失,只有一种类型简化了系统的其他部分。
- 其次,JavaScript 不采用“DRF-SC”或“Catch Fire”规则。相反,像 Java 一样,它仔细定义了竞态访问的可能结果。其理由与 Java 类似,特别是安全性方面。允许竞态读取返回任意值(完全允许,甚至可以说是鼓励)实现返回无关数据,这可能导致运行时泄露私有数据。
- 第三,部分原因是 JavaScript 为竞态程序提供语义,它定义了当原子和非原子操作在同一内存位置使用时的行为,以及当同一内存位置通过不同大小访问时的行为。
精确定义竞态程序的行为会带来松散内存语义的常见复杂性,以及如何禁止“空中楼阁”式读取等问题。除了这些挑战,这些挑战在其他地方也差不多,ES2017 定义中还有两个有趣的漏洞,源自与新 ARMv8 原子指令语义的不匹配。这些例子改编自 Conrad Watt 等人 2020 年的论文《修复和机制化 JavaScript 松散内存模型》。
正如我们在上一节中指出的,ARMv8 增加了 ldar 和 stlr 指令,提供顺序一致的原子加载和存储。这些指令是针对 C++ 设计的,而 C++ 并未定义任何带数据竞争程序的行为。因此,不出意外的是,这些指令在竞态程序中的行为与 ES2017 作者的预期不符,特别是它未能满足 ES2017 对竞态程序行为的要求。
Litmus Test:ARMv8 上的 ES2017 竞态读取
这个程序(使用原子操作)能看到 r1 = 0,r2 = 1 吗?
// 线程 1 // 线程 2
x = 1 y = 1
r1 = y x = 2(非原子操作)
r2 = x
C++:可以(数据竞争,什么都可能发生)。
Java:程序无法编写。
ARMv8 使用 ldar/stlr:可以。
ES2017:不可以!(与 ARMv8 矛盾)
在这个程序中,除了 x = 2 之外,所有读写操作都是顺序一致的原子操作:线程 1 使用原子存储写入 x = 1,线程 2 使用非原子存储写入 x = 2。在 C++ 中,这是一个数据竞争,因此结果是不确定的。在 Java 中,这个程序无法编写:变量必须声明为 volatile 或者否则不能原子访问,而“只能有时访问”是不允许的。在 ES2017 中,内存模型不允许 r1 = 0 和 r2 = 1。如果 r1 = 1 且读取到 0,则线程 1 必须在线程 2 开始之前完成,这时非原子存储 x = 2 似乎发生在后面,覆盖了 x = 1,导致原子操作 r2 = x 读到 2。这个解释看起来完全合理,但这不是 ARMv8 处理器的工作方式。
事实证明,对于等效的 ARMv8 指令序列,非原子写入 x 可以被重新排序到原子写入 y 之前,因此这个程序实际上会产生 r1 = 0,r2 = 1。这个在 C++ 中不是问题,因为数据竞争意味着程序什么行为都可能出现,但在 ES2017 中这是个问题,因为它限制竞态行为的结果,不允许出现 r1 = 0,r2 = 1。
由于使用 ARMv8 指令实现顺序一致的原子操作是 ES2017 的一个明确目标,Watt 等人报告说他们建议的修正方案(计划纳入标准的下一次修订中)会适度放宽竞态行为的约束,从而允许上述结果发生。(我不清楚当时“下一次修订”指的是 ES2020 还是 ES2021。)
Watt 等人提出的修改还包括修复第二个漏洞,该漏洞最初由 Watt、Andreas Rossberg 和 Jean Pichon-Pharabod 发现,即一个无数据竞争的程序未被 ES2017 规范赋予顺序一致的语义。该程序如下:
Litmus Test:ES2017 无数据竞争程序
这个程序(使用原子操作)能看到 r1 = 1,r2 = 2 吗?
// 线程 1 // 线程 2
x = 1 x = 2
r1 = x
if (r1 == 1) {
r2 = x // 非原子操作
}
在顺序一致的硬件上:不能。
C++:我不是 C++ 专家,无法确定。
Java:程序无法编写。
ES2017:可以!(违反 DRF-SC 规则)。
在这个程序中,除了标记的 r2 = x 之外,所有读写操作都是顺序一致的原子操作。该程序无数据竞争:非原子读取(r2 = x)只在 r1 = 1 时执行,这证明线程 1 中的 x = 1 发生在线程 2 的 r1 = x 之前,因此也发生在 r2 = x 之前。DRF-SC(无数据竞争的顺序一致性)要求程序必须以顺序一致的方式执行,因此 r1 = 1,r2 = 2 是不可能的,但 ES2017 规范却允许了这种情况。
因此,ES2017 对程序行为的规范同时过于苛刻(不允许竞态程序的真实 ARMv8 行为)又过于宽松(允许无数据竞争程序出现非顺序一致的行为)。如前所述,这些错误已被修正。即便如此,这再次提醒我们,如何准确地用 happens-before 来定义无数据竞争和竞态程序的语义是多么微妙,以及如何让语言内存模型与底层硬件内存模型匹配同样复杂。
值得鼓舞的是,至少目前,JavaScript 避免添加除顺序一致原子操作外的其他原子操作,并抵制了“DRF-SC 或触发异常(Catch Fire)”的问题。这样产生的内存模型既适合作为 C/C++ 的编译目标,又更接近 Java 的内存模型。
Conclusions
看待 C、C++、Java、JavaScript、Rust 和 Swift 时,我们可以做出以下观察:
- 它们都提供顺序一致的同步原子操作,用于协调并行程序中的非原子部分。
- 它们都旨在保证通过适当同步实现的数据竞争自由程序的行为,表现得如同以顺序一致的方式执行。
- Java 一直到 Java 9 引入 VarHandle 之前,都抗拒添加弱(acquire/release)同步原子操作。JavaScript 则避免添加它们,直到撰写本文时。
- 它们都为程序提供了一种执行“有意”的数据竞争的方式,而不会使程序的其余部分无效。在 C、C++、Rust 和 Swift 中,这种机制是松散的、非同步的原子操作,是一种特殊形式的内存访问。在 Java 中,这种机制要么是普通内存访问,要么是 Java 9 中 VarHandle 的“plain”访问模式。在 JavaScript 中,这种机制是普通内存访问。
- 没有任何语言找到正式禁止诸如“空中阁楼值(out-of-thin-air values)”这类悖论的方法,但所有语言非正式地禁止它们。
与此同时,处理器制造商似乎已经接受了顺序一致同步原子操作这一抽象的重要性,且开始高效实现它:ARMv8 和 RISC-V 都提供了直接支持。
最后,大量的验证和形式化分析工作已经投入到理解这些系统并精确定义其行为中。尤其令人鼓舞的是,Watt 等人在 2020 年成功给出了 JavaScript 的一个重要子集的形式模型,并使用定理证明器证明了将其编译到 ARM、POWER、RISC-V 和 x86-TSO 的正确性。
在第一个 Java 内存模型发布二十五年后,经过大量人年的研究努力,我们可能正开始能够形式化完整的内存模型。也许有一天,我们将完全理解它们。
本系列的下一篇文章是《Updating the Go Memory Model》。
Acknowledgements(致谢)
这一系列文章得益于我在谷歌有幸合作的一长串工程师们的讨论和反馈。在此感谢他们。所有错误或不受欢迎的观点由我本人全权负责。