转载 | Hardware Memory Models
Hardware Memory Models
Introduction: A Fairy Tale, Ending导言: 童话,结局
A long time ago, when everyone wrote single-threaded programs, one of the most effective ways to make a program run faster was to sit back and do nothing. Optimizations in the next generation of hardware and the next generation of compilers would make the program run exactly as before, just faster. During this fairy-tale period, there was an easy test for whether an optimization was valid: if programmers couldn’t tell the difference (except for the speedup) between the unoptimized and optimized execution of a valid program, then the optimization was valid. That is, valid optimizations do not change the behavior of valid programs.
很久以前,当每个人都在编写单线程程序时,要想让程序运行得更快,最有效的方法之一就是坐视不管。下一代硬件和下一代编译器的优化会让程序运行得和以前一模一样,只是速度更快而已。在这个童话般的时期,有一个简单的测试方法来检验优化是否有效:如果程序员无法分辨一个有效程序在未优化和优化后执行的区别(除了速度提升),那么这个优化就是有效的。也就是说,有效的优化不会改变有效程序的行为。
One sad day, years ago, the hardware engineers’ magic spells for making individual processors faster and faster stopped working. In response, they found a new magic spell that let them create computers with more and more processors, and operating systems exposed this hardware parallelism to programmers in the abstraction of threads. This new magic spell—multiple processors made available in the form of operating-system threads—worked much better for the hardware engineers, but it created significant problems for language designers, compiler writers and programmers.
多年前的一个悲伤日子,硬件工程师们让单个处理器越来越快的魔咒失灵了。为此,他们找到了一个新的法宝,可以让他们创造出拥有越来越多处理器的计算机,而操作系统则以线程的抽象形式将这种硬件并行性展现给程序员。这个新法术--以操作系统线程的形式提供多个处理器--对硬件工程师来说效果更好,但却给语言设计者、编译器编写者和程序员带来了巨大的问题。
Many hardware and compiler optimizations that were invisible (and therefore valid) in single-threaded programs produce visible changes in multithreaded programs. If valid optimizations do not change the behavior of valid programs, then either these optimizations or the existing programs must be declared invalid. Which will it be, and how can we decide?
许多在单线程程序中不可见(因此有效)的硬件和编译器优化,在多线程程序中会产生可见的变化。如果有效的优化不会改变有效程序的行为,那么这些优化或现有程序都必须宣布无效。究竟是哪种情况,我们又该如何判断呢?
Here is a simple example program in a C-like language. In this program and in all programs we will consider, all variables are initially set to zero.
下面是一个类似 C 语言的简单示例程序。在这个程序中,以及在我们将要讨论的所有程序中,所有变量的初始值都是零。

If thread 1 and thread 2, each running on its own dedicated processor, both run to completion, can this program print 0?
如果线程 1 和线程 2 都运行在各自专用的处理器上,并且都运行完成,这个程序能打印 0 吗?
It depends. It depends on the hardware, and it depends on the compiler. A direct line-for-line translation to assembly run on an x86 multiprocessor will always print 1. But a direct line-for-line translation to assembly run on an ARM or POWER multiprocessor can print 0. Also, no matter what the underlying hardware, standard compiler optimizations could make this program print 0 or go into an infinite loop.
这要看情况。这取决于硬件,也取决于编译器。在 x86 多处理器上运行的汇编程序逐行直接转换总是打印 1,但在 ARM 或 POWER 多处理器上运行的汇编程序逐行直接转换可能打印 0。但是,在 ARM 或 POWER 多处理器上直接逐行转换为汇编程序运行时,可能会打印 0。此外,无论底层硬件如何,标准编译器优化都可能使该程序打印 0 或进入一个无限循环。(进入无限循环应该是由于内存可见性,没有使用适当同步机制)
“It depends” is not a happy ending. Programmers need a clear answer to whether a program will continue to work with new hardware and new compilers. And hardware designers and compiler developers need a clear answer to how precisely the hardware and compiled code are allowed to behave when executing a given program. Because the main issue here is the visibility and consistency of changes to data stored in memory, that contract is called the memory consistency model or just memory model.
"看情况而定 "不是一个好的结局。程序员需要一个明确的答案,以确定程序是否能在新硬件和新编译器下继续运行。而硬件设计人员和编译器开发人员也需要一个明确的答案,即在执行特定程序时,硬件和编译后的代码可以有怎样的精确行为。因为这里的主要问题是存储在内存中的数据变化的可见性和一致性,所以这种契约被称为内存一致性模型或内存模型。
Originally, the goal of a memory model was to define what hardware guaranteed to a programmer writing assembly code. In that setting, the compiler is not involved. Twenty-five years ago, people started trying to write memory models defining what a high-level programming language like Java or C++ guarantees to programmers writing code in that language. Including the compiler in the model makes the job of defining a reasonable model much more complicated.
最初,内存模型的目标是为编写汇编代码的程序员定义硬件保证。在这种情况下,编译器并不参与其中。25 年前,人们开始尝试编写内存模型,确定 Java 或 C++ 等高级编程语言对编写该语言代码的程序员的保证。将编译器包含在模型中,使得建立合理模型的工作变得更加复杂。
This is the first of a pair of posts about hardware memory models and programming language memory models, respectively. My goal in writing these posts is to build up background for discussing potential changes we might want to make in Go’s memory model. But to understand where Go is and where we might want to head, first we have to understand where other hardware memory models and language memory models are today and the precarious paths they took to get there.
这是分别关于硬件内存模型和编程语言内存模型的两篇文章中的第一篇。我写这两篇文章的目的是为讨论我们可能希望对 Go 的内存模型进行的潜在修改积累背景资料。但是,要了解 Go 的现状以及我们可能想要的方向,我们首先必须了解其他硬件内存模型和语言内存模型的现状,以及它们在实现目标的过程中所走过的崎岖道路。
Again, this post is about hardware. Let’s assume we are writing assembly language for a multiprocessor computer. What guarantees do programmers need from the computer hardware in order to write correct programs? Computer scientists have been searching for good answers to this question for over forty years.
还是那句话,这篇文章是关于硬件的。假设我们正在为多处理器计算机编写汇编语言。为了编写出正确的程序,程序员需要计算机硬件提供哪些保证?四十多年来,计算机科学家一直在寻找这个问题的答案。
Sequential Consistency
Leslie Lamport’s 1979 paper “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs” introduced the concept of sequential consistency:
莱斯利-兰波特在 1979 年发表的论文《如何制造能正确执行多进程程序的多处理器计算机》中提出了顺序一致性的概念:
The customary approach to designing and proving the correctness of multiprocess algorithms for such a computer assumes that the following condition is satisfied: the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. A multiprocessor satisfying this condition will be called sequentially consistent.
为这种计算机设计和证明多进程算法正确性的惯常方法假定满足以下条件:任何执行的结果都与所有处理器的操作按某种顺序执行的结果相同,而且每个处理器的操作都按其程序指定的顺序出现在该顺序中。满足这一条件的多处理器被称为顺序一致处理器。
Today we talk about not just computer hardware but also programming languages guaranteeing sequential consistency, when the only possible executions of a program correspond to some kind of interleaving of thread operations into a sequential execution. Sequential consistency is usually considered the ideal model, the one most natural for programmers to work with. It lets you assume programs execute in the order they appear on the page, and the executions of individual threads are simply interleaved in some order but not otherwise rearranged.
今天,我们谈论的不仅是计算机硬件,还包括保证顺序一致性的编程语言,即程序的唯一可能执行方式是将线程操作交织成顺序执行。顺序一致性通常被认为是理想的模型,是程序员最自然的工作模式。它允许你假设程序按照页面上显示的顺序执行,而单个线程的执行只是按照某种顺序交错进行,但不会以其他方式重新排列。
One might reasonably question whether sequential consistency should be the ideal model, but that’s beyond the scope of this post. I will note only that considering all possible thread interleavings remains, today as in 1979, “the customary approach to designing and proving the correctness of multiprocess algorithms.” In the intervening four decades, nothing has replaced it.
我们有理由质疑,顺序一致性是否应该是理想的模式。理想模式,但这超出了本篇文章的讨论范围。我只想指出,考虑所有可能的线程交错,在今天和 1979 年一样,仍然是 "设计和证明多进程算法正确性的惯用方法"。在这四十年间,没有任何东西可以取代它。
Earlier I asked whether this program can print 0:

To make the program a bit easier to analyze, let’s remove the loop and the print and ask about the possible results from reading the shared variables:
为了让程序更容易分析,让我们删除循环和打印,并询问读取共享变量可能产生的结果:

We assume every example starts with all shared variables set to zero. Because we’re trying to establish what hardware is allowed to do, we assume that each thread is executing on its own dedicated processor and that there’s no compiler to reorder what happens in the thread: the instructions in the listings are the instructions the processor executes. The name rN denotes a thread-local register, not a shared variable, and we ask whether a particular setting of thread-local registers is possible at the end of an execution.
我们假设每个示例开始时所有共享变量都设置为零。因为我们试图确定硬件可以做什么,所以我们假设每个线程都在自己专用的处理器上执行,没有编译器对线程中发生的事情重新排序:列表中的指令就是处理器执行的指令。rN 表示线程本地寄存器,而不是共享变量,我们要问的是,在执行结束时,线程本地寄存器的特定设置是否可行。
This kind of question about execution results for a sample program is called a litmus test. Because it has a binary answer—is this outcome possible or not?—a litmus test gives us a clear way to distinguish memory models: if one model allows a particular execution and another does not, the two models are clearly different. Unfortunately, as we will see later, the answer a particular model gives to a particular litmus test is often surprising.
这种关于示例程序执行结果的问题被称为(litmus test, 美俚语)试金石测试。因为它有两种答案--这个结果是可能的还是不可能的--所以试金石测试为我们提供了一种区分内存模型的明确方法:如果一种模型允许某种特定的执行,而另一种不允许,那么这两种模型显然是不同的。不幸的是,正如我们稍后将看到的,特定模型对特定试金石测试给出的答案往往出人意料。
If the execution of this litmus test is sequentially consistent, there are only six possible interleavings:
如果这个试金石的执行是等价一致的,那么只有六种可能的交错:
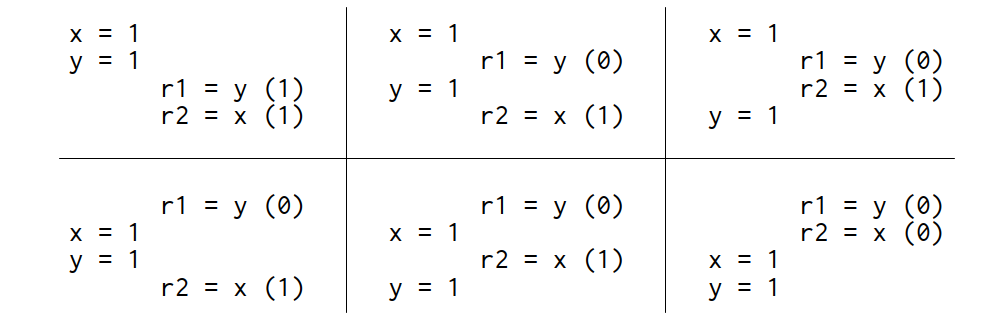
Since no interleaving ends with r1 = 1, r2 = 0, that result is disallowed. That is, on sequentially consistent hardware, the answer to the litmus test—can this program see r1 = 1, r2 = 0?—is no.
由于没有任何交织结果是以 r1 = 1,r2 = 0 结束的,因此该结果是不允许的。也就是说,在顺序一致的硬件上,试金石测试的答案是否定的--这个程序能否看到 r1 = 1,r2 = 0?
A good mental model for sequential consistency is to imagine all the processors connected directly to the same shared memory, which can serve a read or write request from one thread at a time. There are no caches involved, so every time a processor needs to read from or write to memory, that request goes to the shared memory. The single-use-at-a-time shared memory imposes a sequential order on the execution of all the memory accesses: sequential consistency.
顺序一致性的一个很好的思维模型是想象所有处理器直接连接到同一个共享内存,该共享内存可以同时满足一个线程的读取或写入请求。这里不涉及缓存,因此每次处理器需要读取或写入内存时,请求都会进入共享内存。一次性使用的共享内存对所有内存访问的执行都规定了顺序:顺序一致性。

This diagram is a model for a sequentially consistent machine, not the only way to build one. Indeed, it is possible to build a sequentially consistent machine using multiple shared memory modules and caches to help predict the result of memory fetches, but being sequentially consistent means that machine must be-have indistinguishably from this model. If we are simply trying to understand what sequentially consistent execution means, we can ignore all of those possible implementation complications and think about this one model.
本图是顺序一致机器的模型,而不是构建顺序一致机器的唯一方法。事实上,我们可以利用多个共享内存模块和缓存来帮助预测内存获取的结果,从而构建一个顺序一致的机器,但顺序一致意味着该机器必须与此模型无异。如果我们只是想了解顺序一致执行的含义,我们可以忽略所有这些可能的实现复杂性,只考虑这一个模型。
Unfortunately for us as programmers, giving up strict sequential consistency can let hardware execute programs faster, so all modern hardware deviates in various ways from sequential consistency. Defining exactly how specific hardware deviates turns out to be quite difficult. This post uses as two examples two memory models present in today’s widely-used hardware: that of the x86, and that of the ARM and POWER processor families.
不幸的是,对于我们程序员来说,放弃严格的顺序一致性可以让硬件更快地执行程序,因此所有现代硬件都以各种方式偏离顺序一致性。要准确判断特定硬件是如何偏离顺序一致性的,是一件相当困难的事情。本文章以当今广泛使用的硬件中的两种内存模型为例:x86 以及 ARM 和 POWER 处理器系列。
x86 Total Store Order (x86-TSO)
The memory model for modern x86 systems corresponds to this hardware diagram:
现代 x86 系统的内存模型与此硬件图相对应:
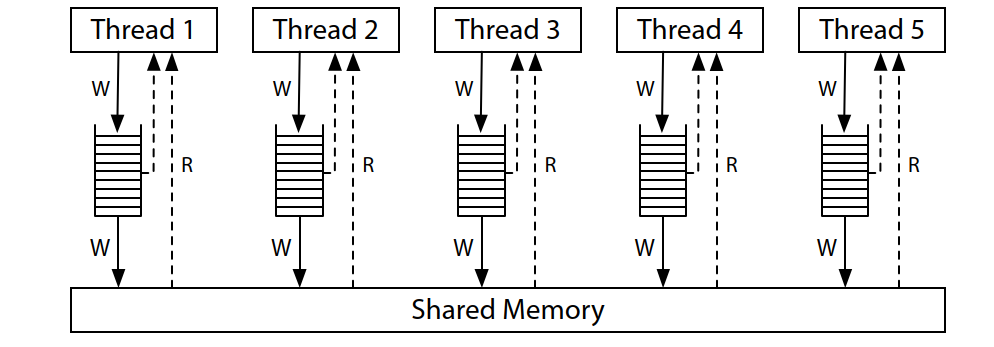
All the processors are still connected to a single shared memory, but each processor queues writes to that memory in a local write queue. The processor continues executing new instructions while the writes make their way out to the shared memory. A memory read on one processor consults the local write queue before consulting main memory, but it cannot see the write queues on other processors. The effect is that a processor sees its own writes before others do. But—and this is very important—all processors do agree on the (total) order in which writes (stores) reach the shared memory, giving the model its name: total store order, or TSO. At the moment that a write reaches shared memory, any future read on any processor will see it and use that value (until it is overwritten by a later write, or perhaps by a buffered write from another processor).
所有处理器仍连接到单个共享内存,但每个处理器都在本地写入队列中排队写入该内存。处理器在写入共享内存的同时继续执行新指令。一个处理器读取内存时,会先查询本地写入队列,然后再查询主内存,但它看不到其他处理器上的写入队列。这样做的后果是,处理器会比其他处理器先看到自己的写入。但是--这一点非常重要--所有处理器都同意写入(存储)到达共享内存的(总)顺序,因此该模型被命名为:总存储顺序,或 TSO。在写入到达共享内存的那一刻,任何处理器上未来的读取都会看到并使用该值(直到该值被后来的写入覆盖,或者被其他处理器建立的写入覆盖)。
The write queue is a standard first-in, first-out queue: the memory writes are applied to the shared memory in the same order that they were executed by the processor. Because the write order is preserved by the write queue, and because other processors see the writes to shared memory immediately, the message passing litmus test we considered earlier has the same outcome as before: r1 = 1, r2 = 0 remains impossible.
写入队列是一个标准的先进先出队列:内存写入的顺序与处理器执行的顺序相同。由于写入队列保留了写入顺序,而且其他处理器会立即看到写入共享内存的内容,因此我们之前考虑过的消息传递试金石测试结果与之前相同:r1 = 1,r2 = 0 仍然是不可能的。

The write queue guarantees that thread 1 writes x to memory before y, and the system-wide agreement about the order of memory writes (the total store order) guarantees that thread 2 learns of x’s new value before it learns of y’s new value. Therefore it is impossible for r1 = y to see the new y without r2 = x also seeing the new x. The store order is crucial here: thread 1 writes x before y, so thread 2 must not see the write to y before the write to x.
写入队列保证线程 1 在写入 y 之前将 x 写入内存,而全系统对内存写入顺序(总存储顺序)的约定则保证线程 1 在写入 y 之前将 x 写入内存。全系统对内存写入顺序(总存储顺序)的一致保证了线程 2 在得知 y 的新值之前,先得知 x 的新值。因此,如果没有 r2 = x 也看到新的 x,r1 = y 就不可能看到新的 y。存储顺序在这里至关重要:线程 1 在写入 y 之前写入 x,因此线程 2 在写入 x 之前一定看不到写入 y 的内容。
The sequential consistency and TSO models agree in this case, but they disagree about the results of other litmus tests. For example, this is the usual example distinguishing the two models:
在这种情况下,顺序一致性模型和 TSO 模型是一致的,但它们在其他试金石测试的结果上存在分歧。例如,这是区分两种模型的常见例子:

In any sequentially consistent execution, either x = 1 or y = 1 must happen first, and then the read in the other thread must observe it, so r1 = 0, r2 = 0 is impossible. But on a TSO system, it can happen that Thread 1 and Thread 2 both queue their writes and then read from memory before either write makes it to memory, so that both reads see zeros.
在任何顺序一致的执行中,x = 1 或 y = 1 必须首先发生,然后另一个线程的读取必须观察到它,因此 r1 = 0, r2 = 0 是不可能的。但在 TSO 系统中,线程 1 和线程 2 都会排队等待写入,然后在任何一个写入到达内存之前从内存中读取,这样两个读取都会看到零。
This example may seem artificial, but using two synchronization variables does happen in well-known synchronization algorithms, such as Dekker’s algorithm or Peterson’s algorithm, as well as ad hoc schemes. They break if one thread isn’t seeing all the writes from another.
这个例子看似很特别,但在德克算法或彼得森算法等著名同步算法以及特别方案中,使用两个同步变量的情况确实存在。如果一个线程没有看到另一个线程的所有写入,它们就会崩溃。
To fix algorithms that depend on stronger memory ordering, non-sequentially-consistent hardware supplies explicit instructions called memory barriers (or fences) that can be used to control the ordering. We can add a memory barrier to make sure that each thread flushes its previous write to memory before starting its read:
为了优化依赖于更强内存排序的算法,非顺序一致性硬件提供了称为内存屏障(或栅栏)的显式指令,可用于控制排序。我们可以添加内存栅栏,确保每个线程在开始读取之前,先清除之前写入内存的内容:
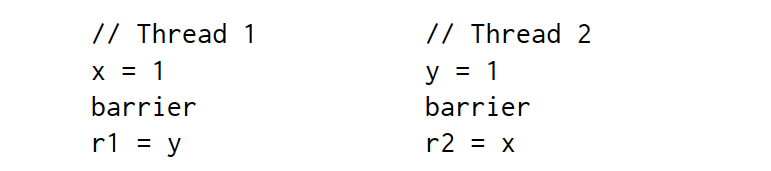
With the addition of the barriers, r1 = 0, r2 = 0 is again impossible, and Dekker’s or Peterson’s algorithm would then work correctly. There are many kinds of barriers; the details vary from system to system and are beyond the scope of this post. The point is only that barriers exist and give programmers or language implementers a way to force sequentially consistent behavior at critical moments in a program.
增加障碍后,r1 = 0、r2 = 0 又是不可能的,这样德克或彼得森的算法就能正确运行了。障碍有很多种,具体情况因系统而异,不在本文讨论范围之内。问题的关键在于,障碍的存在为程序员或语言实现者提供了一种在程序关键时刻强制执行顺序一致行为的方法。
One final example, to drive home why the model is called total store order. In the model, there are local write queues but no caches on the read path. Once a write reaches main memory, all processors not only agree that the value is there but also agree about when it arrived relative to writes from other processors. Consider this litmus test:
举一个例子来说明为什么这个模型被称为 " total store order"。在该模型中,有本地写入队列,但读取路径上没有缓存。一旦写入内容到达主内存,所有处理器不仅会一致同意该值存在,还会一致同意该值相对于其他处理器写入内容的到达时间。考虑一下这个试金石:

If Thread 3 sees x change before y, can Thread 4 see y change before x? For x86 and other TSO machines, the answer is no: there is a total order over all stores (writes) to main memory, and all processors agree on that order, subject to the wrinkle that each processor knows about its own writes before they reach main memory.
如果线程 3 在 y 之前看到 x 的变化,那么线程 4 能否在 x 之前看到 y 的变化?对于 x86 和其他 TSO 机器,答案是否定的:所有存储(写入)到主内存的操作都有一个总的顺序,所有处理器都同意这个顺序,但有一个小问题,即每个处理器在写入到主内存之前都知道自己的写入操作。
The Path to x86-TSO
The x86-TSO model seems fairly clean, but the path there was full of roadblocks and wrong turns. In the 1990s, the manuals available for the first x86 multiprocessors said next to nothing about the memory model provided by the hardware.
x86-TSO 模型看起来相当简洁,但在实现这一目标的道路上却充满了障碍和弯路。20 世纪 90 年代,第一代 x86 多核处理器的使用手册几乎没有提及硬件提供的内存模型。
As one example of the problems, Plan 9 was one of the first true multiprocessor operating systems (without a global kernel lock) to run on the x86. During the port to the multiprocessor Pentium Pro, in 1997, the developers stumbled over unexpected behavior that boiled down to the write queue litmus test. A subtle piece of synchronization code assumed that r1 = 0, r2 = 0 was impossible, and yet it was happening. Worse, the Intel manuals were vague about the memory model details.
Plan 9 是第一个在 x86 处理器上运行的真正的多处理器操作系统(没有全局内核锁),这就是问题的一个例子。1997 年,在移植到多处理器 Pentium Pro 的过程中,开发人员偶然发现了一些意想不到的行为,这些行为可以归结为写入队列试金石测试。一段微妙的同步代码假定 r1 = 0,r2 = 0 是不可能的,但却发生了。更糟糕的是,英特尔手册对内存模型的细节含糊其辞。
In response to a mailing list suggestion that “it’s better to be conservative with locks than to trust hardware designers to do what we expect,” one of the Plan 9 developers explained the problem well:
针对邮件列表中有人提出的 "与其相信硬件设计人员会按我们的期望行事,不如对锁采取保守的态度 "的建议,Plan 9 的一位开发人员很好地解释了这个问题:
I certainly agree. We are going to encounter more relaxed ordering in multiprocessors. The question is, what do the hardware designers consider conservative? Forcing an interlock at both the beginning and end of a locked section seems to be pretty conservative to me, but I clearly am not imaginative enough. The Pro manuals go into excruciating detail in describing the caches and what keeps them coherent but don’t seem to care to say anything detailed about execution or read ordering. The truth is that we have no way of knowing whether we’re conservative enough.
我当然同意。我们将在多处理器中遇到更宽松的排序。问题是,硬件设计人员认为什么是保守的?在锁定部分的开头和结尾强制联锁在我看来是相当保守的,但我显然没有足够的想象力。专业手册详细描述了缓存和保持缓存一致性的方法,但似乎并不关心执行或读取顺序的细节。事实上,我们根本无法知道自己是否足够保守。
During the discussion, an architect at Intel gave an informal explanation of the memory model, pointing out that in theory even multiprocessor 486 and Pentium systems could have produced the r1 = 0, r2 = 0 result, and that the Pentium Pro simply had larger pipelines and write queues that exposed the behavior more often.
在讨论过程中,英特尔公司的一位架构师对内存模型作了非正式的解释,他指出,从理论上讲,即使是多处理器 486 和奔腾系统也可能产生 r1 = 0、r2 = 0 的结果,奔腾 Pro 只是拥有更大的流水线和写入队列,从而更频繁地暴露出这种行为。
The Intel architect also wrote:Loosely speaking, this means the ordering of events originating from any one processor in the system, as observed by other processors, is always the same. However, different observers are allowed to disagree on the interleaving of events from two or more processors. Future Intel processors will implement the same memory ordering model.
英特尔架构师还写道: 从广义上讲,这意味着其他处理器观察到的来自系统中任何一个处理器的事件的排序总是相同的。但是,不同的观察者可以对来自两个或多个处理器的事件的交错顺序产生分歧。未来的英特尔处理器将采用相同的内存排序模型。
The claim that “different observers are allowed to disagree on the interleaving of events from two or more processors” is saying that the answer to the IRIW litmus test can answer “yes” on x86, even though in the previous section we saw that x86 answers “no.” How can that be?
所谓 "允许不同的观察者对来自两个或多个处理器的事件交错存在不同意见",就是说,IRIW试金石的答案在 x86 上可以是 "是",尽管在上一节中我们看到 x86 的答案是 "否"。这怎么可能呢?
The answer appears to be that Intel processors never actually answered “yes” to that litmus test, but at the time the Intel architects were reluctant to make any guarantee for future processors. What little text existed in the architecture manuals made almost no guarantees at all, making it very difficult to program against.
答案似乎是,英特尔处理器实际上从未对这一试金石作出 "是 "的回答,但当时的英特尔架构师不愿对未来的处理器作出任何保证。架构手册中仅有的一点文字几乎没有做出任何保证,这使得针对处理器进行编程变得非常困难。
The Plan 9 discussion was not an isolated event. The Linux kernel developers spent over a hundred messages on their mailing list starting in late November 1999 in similar confusion over the guarantees provided by Intel processors.
Plan 9 的讨论并非孤立事件。从 1999 年 11 月底开始,Linux 内核开发人员在他们的邮件列表上花费了一百多条信息,对英特尔处理器提供的保证进行了类似的混乱讨论。
In response to more and more people running into these difficulties over the decade that followed, a group of architects at Intel took on the task of writing down useful guarantees about processor behavior, for both current and future processors. The first result was the “Intel 64 Architecture Memory Ordering White Paper”, published in August 2007, which aimed to “provide software writers with a clear understanding of the results that different sequences of memory access instructions may produce.” AMD published a similar description later that year in the AMD64 Architecture Programmer’s Manual revision 3.14. These descriptions were based on a model called “total lock order + causal consistency” (TLO+CC), intentionally weaker than TSO. In public talks, the Intel architects said that TLO+CC was “as strong as required but no stronger.” In particular, the model reserved the right for x86 processors to answer “yes” to the IRIW litmus test. Unfortunately, the definition of the memory barrier was not strong enough to reestablish sequentially-consistent memory semantics, even with a barrier after every instruction. Even worse, researchers observed actual Intel x86 hardware violating the TLO+CC model. For example:
在随后的十年中,越来越多的人遇到了这些问题,英特尔公司的一群架构师开始着手为当前和未来的处理器编写有关处理器行为的有用保证。第一个成果是 2007 年 8 月发布的 "英特尔 64 架构内存排序白皮书",旨在 "让软件编写人员清楚地了解不同的内存访问指令序列可能产生的结果"。同年晚些时候,AMD 在《AMD64 架构程序员手册》3.14 修订版中也发布了类似的说明。这些描述基于一种称为 "总锁定顺序+因果一致性"(TLO+CC)的模型,有意弱化了 TSO。在公开演讲中,英特尔架构师表示 TLO+CC 是 "所需的强度,但没有更强"。特别是,该模型为 x86 处理器保留了在 IRIW 试金石测试中回答 "是 "的权利。遗憾的是,即使在每条指令之后都设置了障碍,内存障碍的定义也不足以重新建立顺序一致的内存语义。更糟糕的是,研究人员观察到实际的英特尔 x86 硬件违反了 TLO+CC 模型。例如

Revisions to the Intel and AMD specifications later in 2008 guaranteed a “no” to the IRIW case and strengthened the memory barriers but still permitted unexpected behaviors that seem like they could not arise on any reasonable hardware. For example:
2008 年晚些时候,英特尔和 AMD 对规范进行了修订,保证了 IRIW 情况下的 "否",并加强了内存障碍,但仍允许出现意外行为,这些行为似乎不可能在任何合理的硬件上出现。例如

To address these problems, Owens et al. proposed the x86-TSO model, based on the earlier SPARCv8 TSO model. At the time they claimed that “To the best of our knowledge, x86-TSO is sound, is strong enough to program above, and is broadly in line with the vendors’ intentions.” A few months later Intel and AMD released new manuals broadly adopting this model.
为了解决这些问题,Owens 等人在早期 SPARCv8 TSO 模型的基础上提出了 x86-TSO 模型。当时他们声称:"据我们所知,x86-TSO 是合理的,足以在上面进行编程,而且与供应商的意图基本一致。几个月后,英特尔和 AMD 发布了新的手册,广泛采用了这一模型。
It appears that all Intel processors did implement x86-TSO from the start, even though it took a decade for Intel to decide to commit to that. In retrospect, it is clear that the Intel and AMD architects were struggling with exactly how to write a memory model that left room for future processor optimizations while still making useful guarantees for compiler writers and assembly-language programmers. “As strong as required but no stronger” is a difficult balancing act.
尽管英特尔花了十年时间才决定采用 x86-TSO,但似乎所有英特尔处理器从一开始就采用了 x86-TSO。现在回过头来看,英特尔和 AMD 的架构师们显然都在苦苦思索,到底该如何编写一个内存模型,既能为未来的处理器优化留有余地,又能为编译器编写者和汇编语言程序员提供有用的保证。"强如所需,但不能更强 "是一种艰难的平衡行为。
ARM/POWER Relaxed Memory Model
Now let’s look at an even more relaxed memory model, the one found on ARM and POWER processors. At an implementation level, these two systems are different in many ways, but the guaranteed memory consistency model turns out to be roughly similar, and quite a bit weaker than x86-TSO or even x86-TLO+CC.
现在,让我们来看看更宽松的内存模型,即 ARM 和 POWER 处理器上的内存模型。ARM 和 POWER 处理器上的内存模型。在实现层面上,这两个系统 在实现层面上,这两个系统在很多方面都有所不同,但保证内存一致性的模型 大致相似,而且比 x86-TSO 甚至 x86-TLO+CC 要弱得多。
The conceptual model for ARM and POWER systems is that each processor reads from and writes to its own complete copy of memory, and each write propagates to the other processors independently, with reordering allowed as the writes propagate.
ARM 和 POWER 系统的概念模型是,每个处理器从自己的完整内存副本读取数据并写入,每个写入都会独立传播到其他处理器,在写入传播过程中允许重新排序。
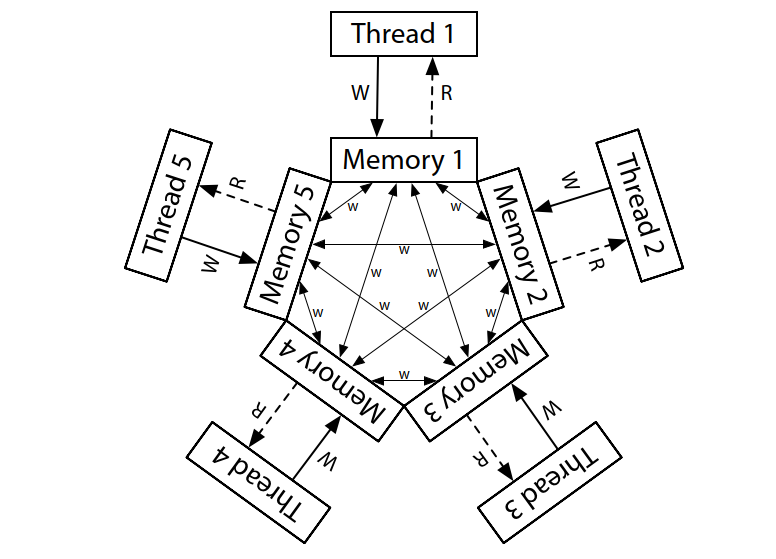
Here, there is no total store order. Not depicted, each processor is also allowed to postpone a read until it needs the result: a read can be delayed until after a later write. In this relaxed model, the answer to every litmus test we’ve seen so far is “yes, that really can happen.”
这里没有总存储顺序。如图所示,每个处理器还可以推迟读取,直到需要结果为止:读取可以延迟到稍后的写入之后。在这个宽松的模型中,我们迄今为止看到的所有试金石的答案都是"是的,这种情况确实可能发生"。
For the original message passing litmus test, the reordering of writes by a single processor means that Thread 1’s writes may not be observed by other threads in the same order:
对于最初的消息传递试金石测试来说,单个处理器对写入内容的重新排序意味着线程 1 的写入内容可能不会被其他线程以相同的顺序观测到:

In the ARM/POWER model, we can think of thread 1 and thread 2 each having their own separate copy of memory, with writes propagating between the memories in any order whatsoever. If thread 1’s memory sends the update of y to thread 2 before sending the update of x, and if thread 2 executes between those two updates, it will indeed see the result r1 = 1, r2 = 0.
在 ARM/POWER 模型中,我们可以认为线程 1 和线程 2 各自拥有独立的内存副本,写入可以以任何顺序在内存之间传播。如果线程 1 的内存先向线程 2 发送 y 的更新,然后再发送 x 的更新,如果线程 2 在这两个更新之间执行,那么它确实会看到 r1 = 1、r2 = 0 的结果。
This result shows that the ARM/POWER memory model is weaker than TSO: it makes fewer requirements on the hardware. The ARM/POWER model still admits the kinds of reorderings that TSO does:
这一结果表明,ARM/POWER 内存模型比 TSO 弱: 它对硬件的要求更低。ARM/POWER 模型仍然进行 TSO 所允许的重新排序:

On ARM/POWER, the writes to x and y might be made to the local memories but not yet have propagated when the reads occur on the opposite threads.
在 ARM/POWER 上,对 x 和 y 的写入可能已经写入本地内存 但当读取发生在相反的线程上时,写入还未传播。
Here’s the litmus test that showed what it meant for x86 to have a total store order:
以下是显示 x86 拥有总存储的意义的试金石 顺序:

On ARM/POWER, different threads may learn about different writes in different orders. They are not guaranteed to agree about a total order of writes reaching main memory, so Thread 3 can see x change before y while Thread 4 sees y change before x.
在 ARM/POWER 上,不同的线程可能以不同的顺序了解不同的写入。它们不能保证在写入主内存的总顺序上达成一致,因此线程 3 可能会在 y 之前看到 x 的变化,而线程 4 则会在 x 之前看到 y 的变化。
As another example, ARM/POWER systems have visible buffering or reordering of memory reads (loads), as demonstrated by this litmus test:
另一个例子是,ARM/POWER 系统在内存读取(加载)过程中会出现明显的分层或重新排序,这个试金石测试就证明了这一点:

Any sequentially consistent interleaving must start with either thread 1’s r1 = x or thread 2’s r2 = y. That read must see a zero, making the outcome r1 = 1, r2 = 1 impossible. In the ARM/POWER memory model, however, processors are allowed to delay reads until after writes later in the instruction stream, so that y = 1 and x = 1 execute before the two reads.
任何顺序一致的交错都必须从线程 1 的 r1 = x 或线程 2 的 r2 = y 开始。不过,在 ARM/POWER 内存模型中,允许处理器将读取延迟到指令流后面的写入之后,这样 y = 1 和 x = 1 就会在两个读取之前执行。
Although both the ARM and POWER memory models allow this result, Maranget et al. reported (in 2012) being able to reproduce it empirically only on ARM systems, never on POWER. Here the divergence between model and reality comes into play just as it did when we examined Intel x86: hardware implementing a stronger model than technically guaranteed encourages dependence on the stronger behavior and means that future, weaker hardware will break programs, validly or not.
虽然 ARM 和 POWER 内存模型都允许出现这一结果,但 Maranget 等人(2012 年)报告说,他们只能在 ARM 系统上根据经验重现这一结果,而从未在 POWER 系统上重现过。在这里,模型与现实之间的差异就像我们研究英特尔 x86 系统时一样发挥作用:实施比技术上保证的更强模型的硬件会鼓励对更强行为的依赖,并意味着未来可能出现的更强行为。对较强行为的依赖,这意味着未来较弱的硬件会破坏程序,无论是否有效。
Like on TSO systems, ARM and POWER have barriers that we can insert into the examples above to force sequentially consistent behaviors. But the obvious question is whether ARM/POWER without barriers excludes any behavior at all. Can the answer to any litmus test ever be “no, that can’t happen?” It can, when we focus on a single memory location.
与 TSO 系统一样,ARM 和 POWER 也有障碍,我们可以在上述示例中插入这些障碍,以强制实现顺序一致的行为。但显而易见的问题是,没有障碍的 ARM/POWER 是否会排除任何行为。任何试金石测试的答案都可能是 "不,这不可能发生? "。当我们专注于单个内存位置时,答案是肯定的。

This litmus test is like the previous one, but now both threads are writing to a single variable x instead of two distinct variables x and y. Threads 1 and 2 write conflicting values 1 and 2 to x, while Thread 3 and Thread 4 both read x twice. If Thread 3 sees x = 1 overwritten by x = 2, can Thread 4 see the opposite?
线程 1 和 2 向 x 写入相互矛盾的值 1 和 2,而线程 3 和线程 4 都读取 x 两次。 如果线程 3 看到 x = 1 被 x = 2 覆盖,那么线程 4 能否看到相反的情况?
The answer is no, even on ARM/POWER: threads in the system must agree about a total order for the writes to a single memory location. That is, threads must agree which writes overwrite other writes. This property is called called coherence. Without the coherence property, processors either disagree about the final result of memory or else report a memory location flip-flopping from one value to another and back to the first. It would be very difficult to program such a system.
答案是否定的,即使在 ARM/POWER 上也是如此:系统中的线程必须就写入单个内存位置的总顺序达成一致。也就是说,线程必须就哪些写入覆盖其他写入达成一致。这一特性被称为一致性。如果没有一致性,处理器要么会对内存的最终结果产生分歧,要么会报告内存位置从一个值跳转到另一个值,然后又回到第一个值。对这样的系统进行编程是非常困难的。
I’m purposely leaving out a lot of subtleties in the ARM and POWER weak memory models. For more detail, see any of Peter Sewell’s papers on the topic. Also, ARMv8 strengthened the memory model by making it “multicopy atomic,” but I won’t take the space here to explain exactly what that means.
我特意忽略了 ARM 和 POWER 弱内存模型中的许多微妙之处。如需了解更多细节,请参阅 Peter Sewell 有关该主题的任何论文。此外,ARMv8 通过使其成为 "多拷贝原子 "来加强内存模型,但我不会在这里花篇幅解释这到底意味着什么。
There are two important points to take away. First, there is an incredible amount of subtlety here, the subject of well over a decade of academic research by very persistent, very smart people. I don’t claim to understand anywhere near all of it myself. This is not something we should hope to explain to ordinary programmers, not something that we can hope to keep straight while debugging ordinary programs. Second, the gap between what is allowed and what is observed makes for unfortunate future surprises. If current hardware does not exhibit the full range of allowed behaviors—especially when it is difficult to reason about what is allowed in the first place!—then inevitably programs will be written that accidentally depend on the more restricted behaviors of the actual hardware. If a new chip is less restricted in its behaviors, the fact that the new behavior breaking your program is technically allowed by the hardware memory model—that is, the bug is technically your fault—is of little consolation. This is no way to write programs.
有两点很重要。首先,这里有令人难以置信的微妙之处,是非常执着、非常聪明的人十多年学术研究的主题。我并不声称自己理解了其中的全部内容。这不是我们应该希望向普通程序员解释的东西,也不是我们可以希望在调试普通程序时保持正确的东西。其次,允许使用的功能与观察到的功能之间的差距会给未来带来不幸的意外。如果当前的硬件没有展示出全部允许的行为--尤其是当推理什么是允许的行为非常困难的时候!那么不可避免的是,编写的程序会意外地依赖于实际硬件中限制较多的行为。如果新芯片的行为限制较少,那么尽管硬件内存模型在技术上允许破坏程序的新行为--也就是说,从技术上讲,错误是你的过失--但这并不能起到什么安慰作用。这不是编写程序的方式。
Weak Ordering and Data-Race-Free Sequential Consistency
By now I hope you’re convinced that the hardware details are complex and subtle and not something you want to work through every time you write a program. Instead, it would help to identify shortcuts of the form “if you follow these easy rules, your program will only produce results as if by some sequentially consistent interleaving.” (We’re still talking about hardware, so we’re still talking about interleaving individual assembly instructions.)
现在,我希望你已经相信,硬件细节是复杂而微妙的,并不是你每次编写程序时都想解决的问题。相反,找出 "如果你遵循这些简单的规则,你的程序就会像通过某种顺序一致的交织一样产生结果 "这种形式的捷径会有所帮助。(我们仍在讨论硬件,所以我们仍在讨论交错单个汇编指令)。
Sarita Adve and Mark Hill proposed exactly this approach in their 1990 paper “Weak Ordering – A New Definition”. They defined “weakly ordered” as follows.
萨里塔-阿德维和马克-希尔在 1990 年发表的论文《弱排序--一个新定义》中提出的正是这种方法。他们将 "弱排序 "定义如下。
Let a synchronization model be a set of constraints on memory accesses that specify how and when synchronization needs to be done. Hardware is weakly ordered with respect to a synchronization model if and only if it appears sequentially consistent to all software that obey the synchronization model.
让同步模型成为一组内存访问的约束条件,这些约束条件规定了同步的方式和时间。当且仅当硬件与所有遵守同步模型的软件在顺序上一致时,硬件在同步模型方面才是弱有序的。
Although their paper was about capturing the hardware designs of that time (not x86, ARM, and POWER), the idea of elevating the discussion above specific designs, keeps the paper relevant today.
虽然他们的论文是关于捕捉当时的硬件设计(而不是 x86、ARM 和 POWER),但将讨论提升到特定设计之上的想法,使这篇论文至今仍具有现实意义。
I said before that “valid optimizations do not change the behavior of valid programs.” The rules define what valid means, and then any hardware optimizations have to keep those programs working as they might on a sequentially consistent machine. Of course, the interesting details are the rules themselves, the constraints that define what it means for a program to be valid.
我之前说过,"有效的优化不会改变有效程序的行为"。规则定义了有效的含义,然后任何硬件优化都必须保持这些程序在顺序一致的机器上正常运行。当然,有趣的细节在于规则本身,即确定程序有效含义的约束条件。
Adve and Hill propose one synchronization model, which they call data-race-free (DRF). This model assumes that hardware has memory synchronization operations separate from ordinary memory reads and writes. Ordinary memory reads and writes may be reordered between synchronization operations, but they may not be moved across them. (That is, the synchronization operations also serve as barriers to reordering.) A program is said to be data-race-free if, for all idealized sequentially consistent executions, any two ordinary memory accesses to the same location from different threads are either both reads or else separated by synchronization operations forcing one to happen before the other.
Adve 和 Hill 提出了一种同步模型,他们称之为无数据链路 (DRF)。该模型假设硬件的内存同步操作与普通内存读写操作是分开的。普通内存读写可以在同步操作之间重新排序,但不能在同步操作之间移动。(也就是说,同步操作也是重新排序的障碍)。如果在所有理想化的顺序一致的执行过程中,来自不同线程对同一位置的任意两次普通内存访问要么都是读取,要么都被同步操作隔开,迫使其中一次先于另一次发生,那么这个程序就被称为无数据竞赛程序。
Let’s look at some examples, taken from Adve and Hill’s paper (redrawn for presentation). Here is a single thread that executes a write of variable x followed by a read of the same variable.
让我们来看看 Adve 和 Hill 论文中的一些例子(为便于演示而重新绘制)。重绘)。下面是一个单线程,它在执行写入变量 x 之后 然后读取同一变量。
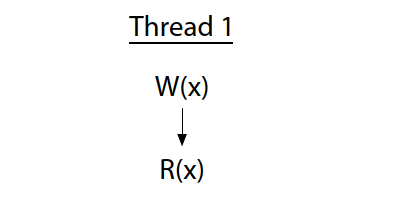
The vertical arrow marks the order of execution within a single thread: the write happens, then the read. There is no race in this program, since everything is in a single thread.
垂直箭头表示单个线程的执行顺序:先写入,然后读取。在这个程序中不存在竞赛,因为一切都在单线程中进行。单线程中。

Here, thread 2 writes to x without coordinating with thread 1. Thread 2’s write races with both the write and the read by thread 1. If thread 2 were reading x instead of writing it, the program would have only one race, between the write in thread 1 and the read in thread 2. Every race involves at least one write: two uncoordinated reads do not race with each other.
在这里,线程 2 在不与线程 1 协调的情况下写入 x。线程 2 的写 与线程 1 的写和读发生竞赛。如果线程 2 读取 x 而不是写入 x,程序将只有一次竞赛,即线程 1 的写入和线程 2 的读取之间的竞赛。线程 1 的写和线程 2 的读之间。每一次竞赛都至少涉及一次写入:两次不协调的读取不会发生竞赛。
To avoid races, we must add synchronization operations, which force an order between operations on different threads sharing a synchronization variable. If the synchronization S(a) (synchronizing on variable a, marked by the dashed arrow) forces thread 2’s write to happen after thread 1 is done, the race is eliminated:
为了避免竞赛,我们必须添加同步操作,强制共享同步变量的不同线程之间的操作顺序。如果同步 S(a)(同步变量 a,用虚线箭头标记)强制线程 2 在线程 1 完成后写入,竞赛就会消除:
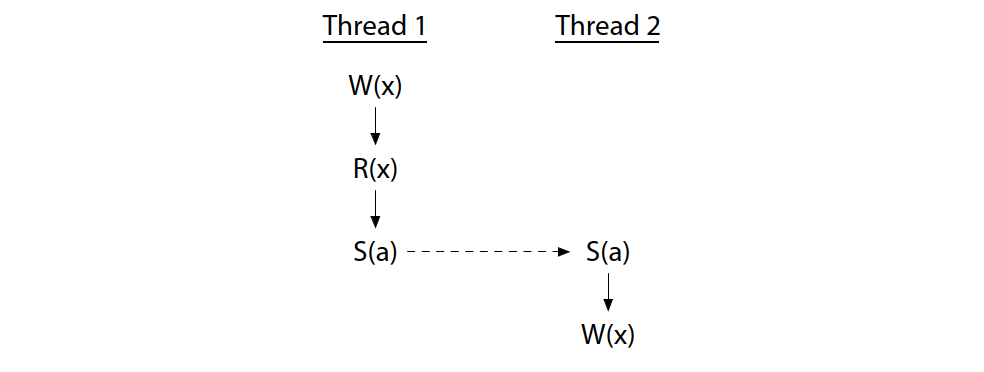
Now the write by thread 2 cannot happen at the same time as thread 1’s operations.
现在,线程 2 的写操作不能与线程 1 的操作同时进行。
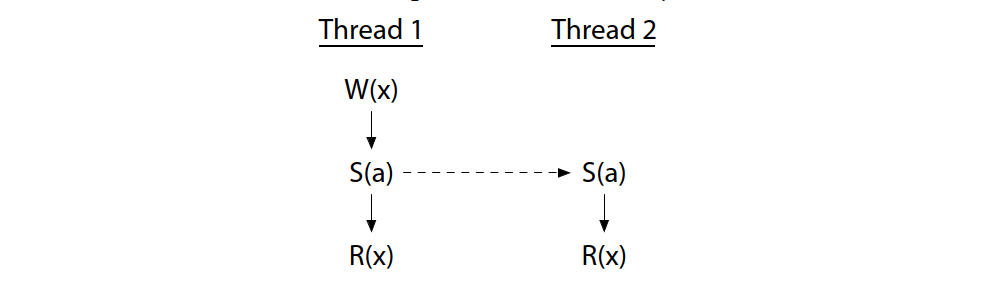
If thread 2 were only reading, we would only need to synchronize with thread 1’s write. The two reads can still proceed concurrently:
如果线程 2 只读取数据,我们只需与线程 1 的写同步即可。两个读取仍然可以同时进行:
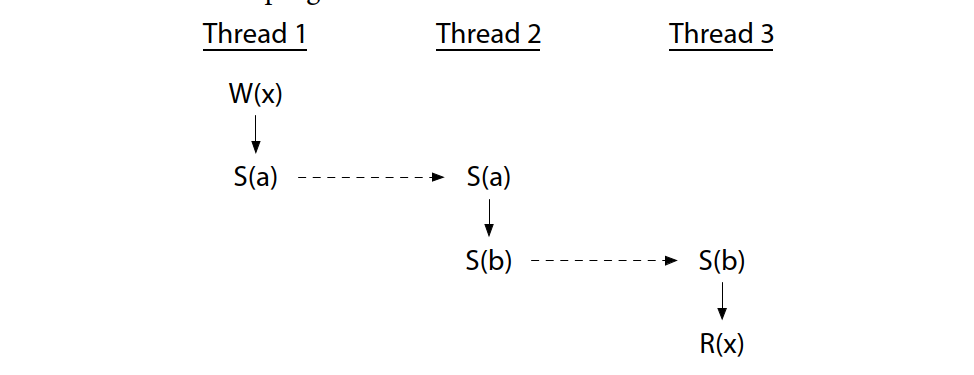
Threads can be ordered by a sequence of synchronizations, even using an intermediate thread. This program has no race:
线程可以通过同步序列排序,甚至可以使用中间线程。这个程序没有竞赛:
On the other hand, the use of synchronization variables does not by itself eliminate races: it is possible to use them incorrectly. This program does have a race:
另一方面,使用同步变量本身并不能消除竞赛:错误使用同步变量也是有可能的。这个程序确实存在竞赛:
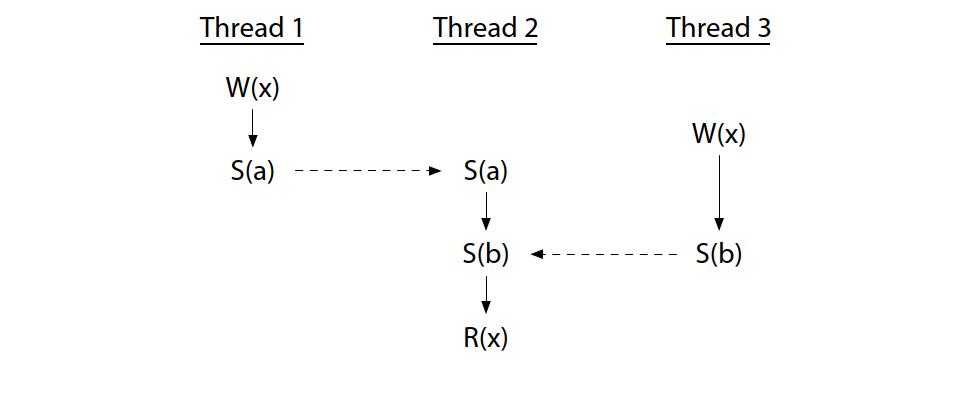
Thread 2’s read is properly synchronized with the writes in the other threads—it definitely happens after both—but the two writes are not themselves synchronized. This program is not data-race-free.
线程 2 的读取与其他线程的写入是同步的--它绝对发生在两个线程之后。但两个写操作本身并不同步。这个程序并非无数据竞赛。
Adve and Hill presented weak ordering as “a contract between software and hardware,” specifically that if software avoids data races, then hardware acts as if it is sequentially consistent, which is easier to reason about than the models we were examining in the earlier sections. But how can hardware satisfy its end of the contract?
Adve 和 Hill 将弱排序说成是 "软件和硬件之间的契约",具体来说,如果软件避免了数据竞赛,那么硬件的行为就好像是顺序一致的,这比我们在前面章节中研究的模型更容易推理。但是,硬件如何才能履行其合约呢?
Adve and Hill gave a proof that hardware “is weakly ordered by DRF,” meaning it executes data-race-free programs as if by a sequentially consistent ordering, provided it meets a set of certain minimum requirements. I’m not going to go through the details, but the point is that after the Adve and Hill paper, hardware designers had a cookbook recipe backed by a proof: do these things, and you can assert that your hardware will appear sequentially consistent to data-race-free programs. And in fact, most relaxed hardware did behave this way and has continued to do so, assuming appropriate implementations of the synchronization operations. Adve and Hill were concerned originally with the VAX, but certainly x86, ARM, and POWER can satisfy these constraints too. This idea that a system guarantees to data-race-free programs the appearance of sequential consistency is often abbreviated DRF-SC.
Adve 和 Hill 证明了硬件 "通过 DRF 弱排序",也就是说,只要满足一组特定的最低要求,硬件就能像通过顺序一致的排序一样执行无数据竞赛程序。我不想细说,但重点是,在 Adve 和 Hill 的论文发表后,硬件设计者就有了一份有证明支持的食谱:只要做到这些,你就可以断言,你的硬件在执行无数据竞序程序时会表现出顺序一致性。而事实上,只要同步操作实现得当,大多数宽松的硬件确实是这样表现的,而且一直如此。Adve 和 Hill 最初关注的是 VAX,但 x86、ARM 和 POWER 当然也能满足这些约束。系统保证无数据race程序的外观顺序一致性,这一观点通常被缩写为 DRF-SC。
DRF-SC marked a turning point in hardware memory models, providing a clear strategy for both hardware designers and software authors, at least those writing software in assembly language. As we will see in the next post, the question of a memory model for a higher-level programming language does not have as neat and tidy an answer.
DRF-SC 标志着硬件内存模型的转折点,为硬件设计者和软件作者(至少是那些用汇编语言编写软件的作者)提供了明确的策略。我们将在下一篇文章中看到,高级编程语言的内存模型问题并没有那么整齐划一。